130-一天学会perl
刘小泽开始写于19.7.31 写这个是因为看到龙星教程使用了大量的perl脚本,动辄4、5千行,例如https://github.com/WGLab/PennCNV/blob/master/filter_cnv.pl 题目不是我取的,我也不知道学不学的会,但总要试试,教程在:Perl Tutorial for Beginners: Learn in 1 Day https://www.guru99.com/perl-tutorials.html
前言
语言不介绍,安装不多说,用
perl -v检查版本写脚本或看别人脚本时首先要注意的就是:
#!/usr/bin/perl这行代码,指定了解释器的路径,并以#!开头,当然有些IDEs不需要指定。另外可以在这行的末尾加上-w表示全局显示warning信息真正写代码时,一句完整的代码要以
;结尾,例如:print "Hello World";引号是操作的字符串关于执行perl脚本:
- Windows:
C:\> perl path\firstprog.pl或C:\> c:\perl\bin\perl.exe firstprog.pl - Linux或Unix:
perl firstprog.pl如果保错找不到这个脚本,就先赋予执行权限:chmod +x firstprog.pl,然后./firstprog
- Windows:
安装CPAN(Comprehensive Perl Archive Network)模块:
什么是模块或者说是module?Modules are set of codes that are used to do tasks that perform common operations in several programs. You do not have to rewrite the codes to perform that same operation.就是别人做好的直接拿来用的函数们,很像R包、Python库
大多数Perl模块用Perl写的,也有用C语言编写,这样的模块需要调用C语言编译器。而且模块之间是相互依赖的,安装时需要注意这种关联
建议使用
cpanminus来获取、解压、安装模块(https://metacpan.org/release/App-cpanminus/) 利用cpan App::cpanminus(当然首先要确保自己系统有cpan这个东西),然后可以安装其他的模块:cpan –i <Module_Name>,例如安装File::Data这个模块就用:cpan -i File::Data(测试)如果发现自己服务器账号上没有
cpan,可以到某个路径下寻找,例如# 运行perl脚本经常会报错,显示没有某个模块,因为有时脚本会调用(require xxx.pm) # 比如我缺少khmm.pm这个模块,当前用户又没有,只能调用公共路径下的,然后安装到自己路径(local::lib,也是默认选项) /shared/Perl/bin/cpan -i khmm.pm
Perl 变量
什么是变量?
可以将变量想象成一类容器,能存储一个或多个值。一旦指定了值,那么这个变量的类型也就确定了,但是其中的值是可以不断改变的
三类变量:
标量(scalar)
存储一个值,用
$variable_name表示变量都有命名规则,关于标量命名有三个注意事项
所有标量都以
$开头然后可以接字母或者数字,可以用
a to z, A to Z and 0 to 9,下划线也可以,只不过不能以数字开头数字可以作为名称的一部分,但是开头还是要用字母或下划线 例如:
$var; $Var32; $vaRRR43; $name_underscore_23;
标量又分为两种类型:数字和字符串
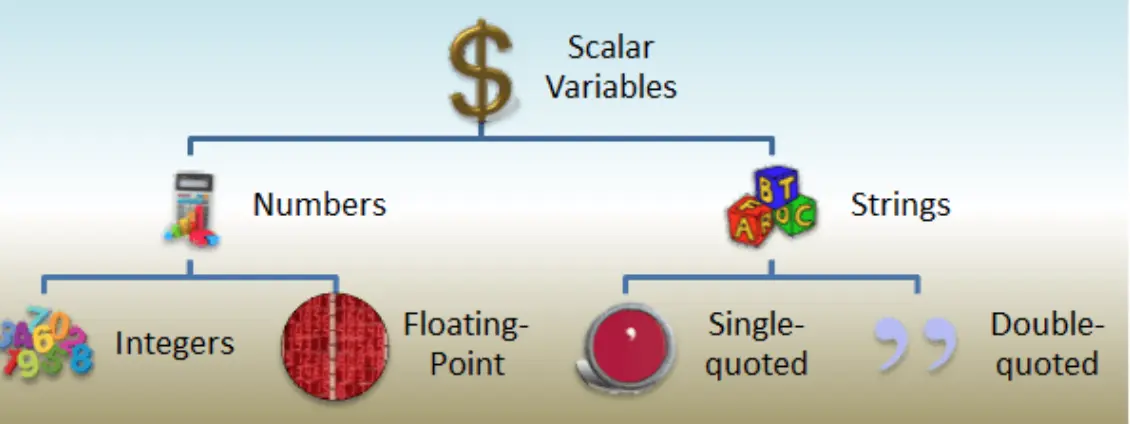
数字:整数(如:2、0)、浮点数(如:3.14、6.35)。perl对待整数也是首先当成浮点数进行理解,例如它会将2理解成2.0000。对于长度较长的数字,也可以用下划线分隔,如:
4865415484645 = 4_865_415_484_645字符串:perl中字符串的长度取决于内存大小,当然最短的字符串也可以是空字符串。有两种表示方法:单引号字符串和双引号字符串。 单引号可以理解为强引用,举个例子:
#!/usr/bin/perl $num = 7; $txt = 'it is $num'; print $txt; # 结果:it is $num # 看到它不会将变量$num输出双引号就可以,它可以调用标量和数组,但是不能直接用在哈希身上(不过可以调用哈希的切片)。最简答的例如:
$num = 7; $txt = "it is $num"; print $txt; # it is 7特殊的:如
\n就是换行符,还有很多: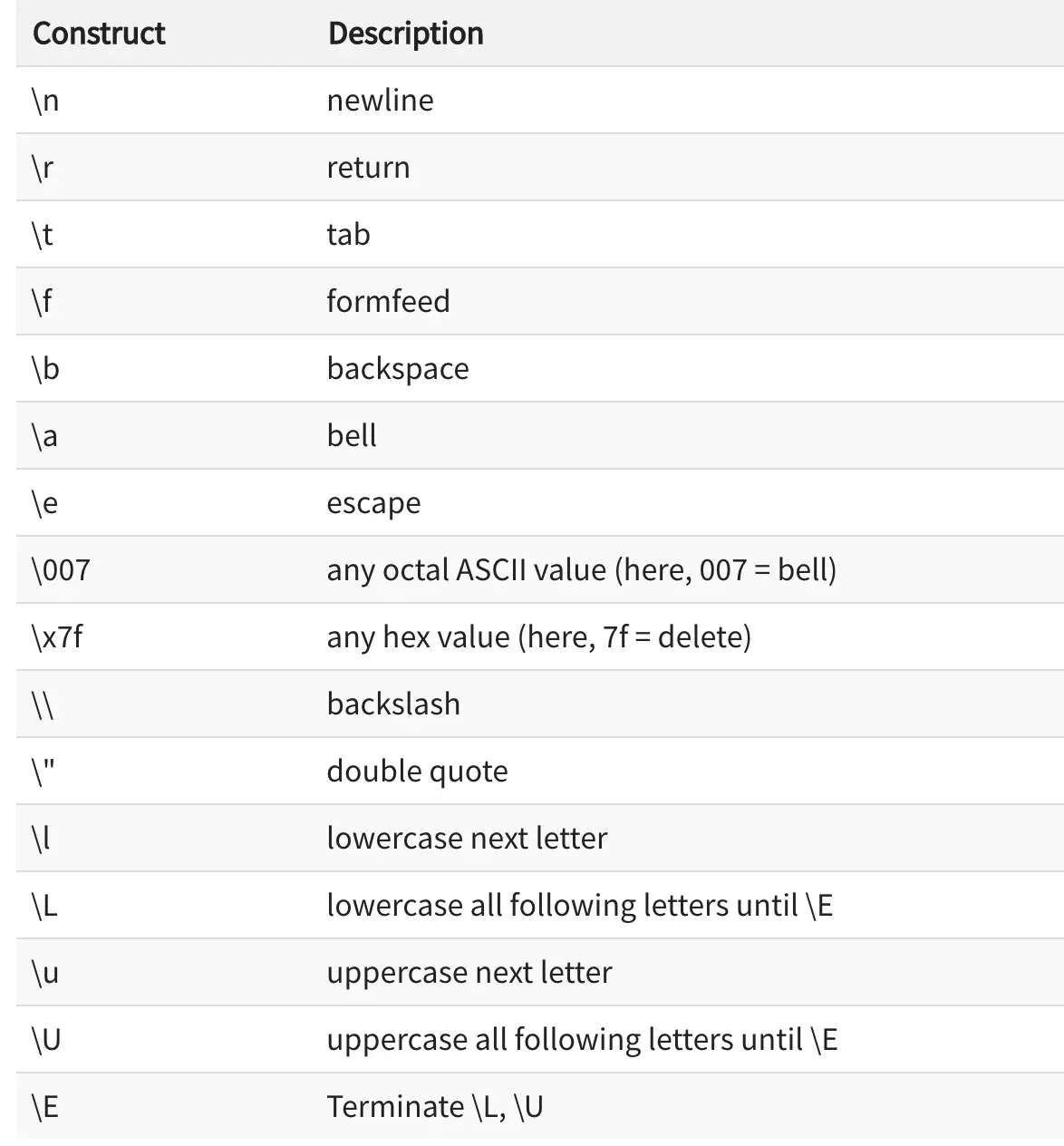
字符串的连接:利用
.,例如:#!/usr/bin/perl $a = "Tom is"; $b = "favorite cat"; $c = $a ." mother's ". $b; print $c; # Tom is mother's favorite cat # 当然,如果要连接的字符串中需要包含引号、反斜线等特殊字符,就需要先将这个字符串用反引号转义,例如:$a = "Tom is\"",结果就会输出 # Tom is" mother's favorite cat关于数字和字符串联合运算:结果取决于使用什么运算符号(之后介绍),例如:
$string = "43"; $number = 28; $result = $string + $number; print $result; # 71(将字符转为了数字)
如果想要在脚本任何位置调用标量变量,就需要用到
Access modifier,主要有3种类型my:这个调用只在一个小范围(block)中有效,例如在一个大括号中#!/usr/bin/perl my $var=5; if(1) { my $var_2 =$var; } print $var_2; # 这样是没有返回结果的 # 解读:可以看到,一共定义了两个变量,一个在block内部(var_2),一个在外部(var)。内部运算的var_2是不能在大括号外访问的。如果将最后一行改成print $var;就会返回结果local:假定之前有一个变量被定义,我们可以用local在小范围内覆盖原来的变量,赋予一个新的值,但不改变原来的变量。例如:#!/usr/bin/perl $var = 5; { local $var = 3; print "local,\$var = $var \n"; } print "global,\$var = $var \n"; # local, $var = 3 # global, $var = 5our:覆盖范围最大的变量调用符号
数组(Array)
以列表的形式存储数据,然后其中的每个元素都有一个唯一的index,可以用来访问。它可以包含数字、字符串等等,利用
@来创建数组,例如my @array;关于存储数据,举个例子:
my @array=(a,b,c,d); print @array; # abcd还有一种方法:利用
qw(),它的意思是quote word,利用空格作为分隔符:@array1=qw/a b c d/; @array2= qw' p q r s'; @array3=qw { v x y z}; print @array1; print @array2; print @array3; # abcdpqrsvxyz需要注意的是:数组是从0开始计数的

如果要在数组中添加某个元素,可以用:
$array [4] ='e';这样就在第5个位置添加了字母e顺序数组(Sequential Array):有点像R中用
seq()生成的结果,例如:@numbers= (1..10); print @numbers; # 12345678910检查数组的大小:两种方法
@array= qw/a b c d e/; print $size=scalar (@array); # 第一种用scalar print "\n"; print $size=$#array + 1; # 第二种用$#array,它会返回最大的index,但是注意perl是0-based,因此总长度要+1好,以上都是静态数组,那么还有一种常用的叫”动态数组",简单理解就是利用循环构建的数组
动态数组?举个例子:
my $string="This is a kind of dynamic array"; my @array; @array=split('a',$string); foreach(@array) { print "$_ \n”; # $_这个特殊变量,存储了当前行的内容 } # 结果会按照a进行字符串的分隔,产生: This is kind of dyn mic rr y数组的元素添加/删除:push、pop、shift、unshift
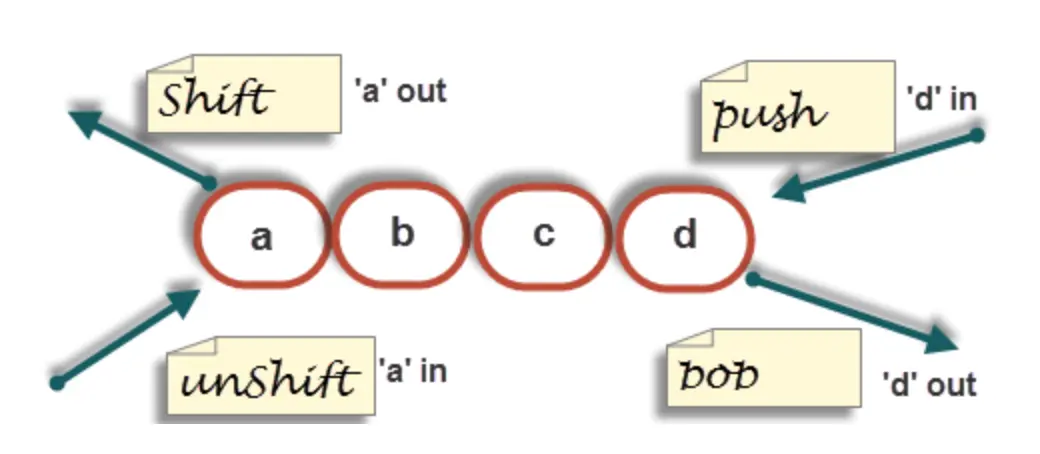
- push:结尾添加
- pop:结尾移除
- shift:开头移除
- unshift:开头添加
哈希(Hashes)
为啥用哈希? 回顾一下,标量变量存储整数、字符串;数组存储一系列标量变量,然后可以利用index来调用,但是这就衍生了一个问题,如果有成百上千个元素呢,怎么访问?我们还要记住每个元素的index吗?因此哈希派上了用场
理论上,哈希可以存储足够多的标量变量,它和数组不同之处在于:它不用index调用,而是用的键值对(key-value),就像Python的字典一样,存储足够多的,用到什么查什么。哈希是用
%调用的,举个例子:@array=('Sainath',23,'Krishna',24,'Shruthi',25); print @array; # Sainath33Krishna24Shruthi25它的经典调用方式是这样的,图中底部文字也显示了如何调用其中的值,也就是说,如果想知道某个人的年龄,只需要知道他的名字:
print $hash{'Krishna'};,其中的$就代表每个哈希元素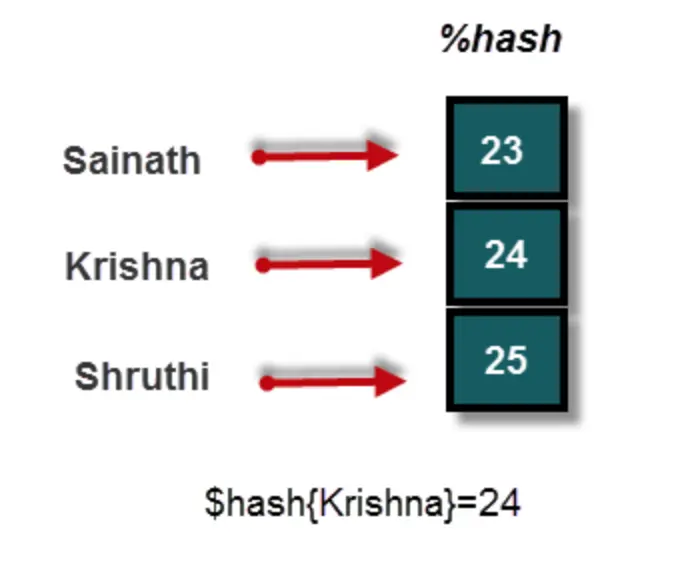
需要注意的是:哈希中的每个键(key)都应该是唯一的,否则它会覆盖原来的值。如何将一个哈希赋值给原来的哈希?
%hash=( 'Tom' => 23); %newHash=%hash; print %newHash; # Tom23如何在哈希中添加键值对?
$newHash{'Jim'}=25; $newHash{'John'}=26; $newHash{'Harry'}=27; print %newHash; # Jim25John26Harry27如何删除?
delete $newHash{'Jim'}; # 这个delete是一个perl的内置函数另外我们可以单独提取键或值:
# 利用keys函数或者values函数 @arraykeys= keys(%newHash); @arrayvalues=values(%newHash); print "@arraykeys\n"; print "@arrayvalues\n";如果再狠一点,删除整个哈希,就可以重置它:
%newHash=();
Perl的条件使用
和大多数其他语言一样,都会涉及不同的条件语法
if条件
my $a=5;
if($a==5)
{
print "The value is $a";
}
# 输出5
if else条件
就是加多一个限制条件
my $a=10;
if($a==5)
{
print "The values is $a ---PASS";
}
else
{
print "The value is $a ---FAIL";
}
# 结果 The value is 10 ---FAIL
elseif条件
my $a=5;
if($a==6)
{
print "Executed If block -- The value is $a";
}
elsif($a==5)
{
print "Executed elsif block --The value is $a";
}
else
{
print "Executed else block – The value is $a";
}
if嵌套
my $a=11;
if($a<10){
print "Inside 1st if block";
if($a<5){
print "Inside 2nd if block --- The value is $a";
}
else{
print " Inside 2nd else block --- The value is $a";
}
}
else{
print "Inside 1st else block – The value is $a";
}
# Inside 1st else block – The value is 11
unless
它和if的意思是相反的,只有当它包含的条件为假时,才会执行它的命令(可以和if对照理解);如果满足unless的条件,那么就会执行它的else命令
my $a=5;
unless($a==5)
{
print "Inside the unless block --- The value is $a";
}
else
{
print "Inside else block--- The value is $a";
}
# 结果是:Inside else block--- The value is 5
Perl循环使用
主要是四种:for, foreach, while and until
for循环
当条件满足时执行,例如:
my @array=(1..10);
for(my $count=0;$count<10;$count++)
{
print "The array index $count value is $array[$count]";
print "\n";
}
# 这个结果会返回类似"The array index 0 value is 1"的10条结果
for的第二种用法
for(1..10)
{
print "$_ n";
print "\n";
}
# 结果会输出1n、2n等,且都是间隔一行
foreach
它就是在for的基础上增加递归,不用手动设定
my @array=(1..10);
foreach my $value (@array)
{
print " The value is $value\n";
}
# 先定义一个数组,然后将数组放入foreach循环,每次循环赋值给value
# 另一种展现方式:利用$_(更常用一点)
my @array=(1..10);
foreach(@array)
{
print " The value is $_ \n";
}
上面是对数组进行foreach操作,那么对哈希呢?
my %hash=( 'Tom' => 23, 'Jerry' => 24, 'Mickey' => 25);
foreach my $key (keys %hash)
{
print "$key \n";
}
#参考上面数组的第二种,我们对哈希也能写出
my %hash=( 'Tom' => 23, 'Jerry' => 24, 'Mickey' => 25);
foreach(keys(%hash))
{
print "$_ \n";
}
# 依次类推,对value也可以调用
while
只有当满足while的条件时才进行循环,不满足就跳出。例如:猜数字的小程序
#!/usr/bin/perl
$guru99 = 0;
$luckynum = 7;
print "Guess a Number Between 1 and 10\n";
$guru99 = <STDIN>;
while ($guru99 != $luckynum)
{
print "Guess a Number Between 1 and 10 \n ";
$guru99 = <STDIN>;
}
print "You guessed the lucky number 7"
# <STDIN>就是键盘输入的数字,如果不等于提前设定的$luckynum=7时,就循环,让你一遍一遍输入,只有输入为7时,才输出恭喜信息
do while循环
要把do和while当成一个整体,语法结构是:
$guru99 = 10;
do {
print "$guru99 \n";
$guru99--;
}
while ($guru99 >= 1);
print "Now value is less than 1";
# 意思是从10递减1,一直减到1,当等于1时还是满足while条件的,那么继续传给do循环,再减1为0。此时不再满足while条件,于是跳出循环,输出结果
until循环
和条件控制的unless很像,当其中的条件为假时才跳出输出
大体语法如下:
print "Enter any name \n";
my $name=<STDIN>;
chomp($name);
until($name ne 'sai')
{
print "Enter any name \n";
$name=<STDIN>;
chomp($name);
}
# 只有当until($name ne 'sai')中的条件$name ne 'sai'为假,也就是$name=sai时才会结束
这个
<STDIN>要注意一下:它用作非文件的标准输入,例如管道传输的数据、重定向的数据或者键盘输入。而且它的输入会自带换行符,因此<>)还有chmop是去掉行尾换行符的意思
Perl运算符(Operator)
Perl整合了C语言的许多运算符,相对于其他语言运算符的数量更多。主要包括:数学运算、赋值、逻辑关系符号
数学运算:主要注意
++、--为每次加/减1,例如:$x++;或++$x;都可以赋值运算:类似
+=、-=这样,例如:$x=4; $x+=10 结果就是14逻辑关系(两种表示方法):
==/eq、!=/ne、>/gt、||、&&
Perl特殊变量
特殊之处就在于:有的变量提前定义好了,然后长得比较奇怪,但是用起来很方便。大部分的特殊变量都是标量变量
特殊的标量变量:(很重要!大多时候看不懂别人的代码就是因为看不懂这些代表什么意思)
举几个例子:更多可以参考:https://www.cnblogs.com/ace9/archive/2011/04/29/2032755.html
$_ 存储当前的变量值 $0 存储perl脚本的名称 $\ 定义输出分隔符 $. 读取的当前行号 $<digit> 例如$1, $2, $3 … :存储匹配得到的第1、2、3...个值
Perl正则表达式
字符串匹配是perl强大的一个原因,虽然现在perl在一点点被遗忘,但是很多好用的脚本还是在流传。好的东西不会被淡忘~
perl 比对用m//,替换用s///
先复习一下表达式
\ 表示特殊字符或引用
* 0或多
+ 1或多
?0或1
| 可选的匹配模式
() 存储匹配模式
关于匹配(match)举个例子:
my $userinput="Guru99 Rocks";
if($userinput=~m/.*(Guru99).*/)
{
print "Found Pattern";
}
else
{
print "unable to find the pattern";
}
# Found Pattern
# 当然 =~ 可以替换成 !~ 表示不匹配
关于替换(Substitution)举个例子:
my $a="Hello how are you";
$a=~s/hello/cello/gi;
print $a;
# 结果是:cello how are you
# 注意:g-globally, i-ignore case
Perl文件操作I/O
一个概念:文件句柄(FILEHANDLE,简称FH,可以理解成文件的代称) ,当打开文件进行读或写时使用
打开文件
利用open()函数:open(FILEHANDLE, "文件名或文件绝对路径");
既然打开了文件,那么接下来是要读还是要写? 具体操作像极了Linux
读 – open(my $fh,"<文件名或文件绝对路径");
写 – open(my $fh,">文件名或文件绝对路径");
追加 – open(my $fh,">>文件名或文件绝对路径");
练习读文件
open(FH,"<file.txt");
while(<FH>) #对读入的每行执行一个循环操作
{
print "$_";
}
close FH;
练习写文件
open(FH,">test.txt");
my $var=<>;
print FH $var;
close FH;
练习追加文件
open(FH,">>test.txt");
my $var=<>;
print FH $var;
close FH;
对文件夹处理
# 实现输出文件夹下的所有文件名
opendir(DIR,"C:\\Program Files\\"); # DIR是一个文件句柄
while(readdir(DIR)) # readdir是内置函数
{
print "$_\n";
}
closedir(DIR); # 结束后要关闭文件句柄
Perl子函数
它和内置的perl函数(print、chmop等)差不多,只不过是我们自己在代码中定义的,确保了函数复用
一般格式:
sub subroutine_name
{
Statements…;
}
知道了怎么定义一个子函数,那么如何调用它呢? 在子函数前面加上一个
&就可以实现,例如:sub hash { my %hash=@_; print %hash; } %value= ( 1=>'a', 2=>'b'); &hash(%value); # 定义了一个叫hash的子函数,内容就是存储+输出。然后我们调用它就用的&hash
将参数传递给子函数
sub add
{
my $a=shift;
my $b=shift;
return($a+$b);
}
my $result=add(5,6);
print $result;
# 结果是11
Perl脚本标准
- 一般建议加上
strict和warnings这两个模块,前者让代码更清晰,后者使代码少报错 - 经常使用反馈性的代码,例如打开文件时,如何检查文件能否正确打开:
open(FH, <file.txt") or die("cannot open the file $!");
比较标准的格式:
#######################################################################
Program to read the file content
# Date: 22-2-2013
# Author : Guru99
########################################################################
#!/usr/bin/perl
use strict;
use warnings;
my $line;
open FR, "file.txt" || die("Cannot open the file $!");
while ($line=<FR>)
{
print $line;
} # Looping file handler to print data
Perl模块
什么是模块?Module is a collection of reusable code, where we write subroutines in it.
标准的模块在perl安装时一起被装好了,有一些自定义的需要下载使用,一般以.pm结尾,用require调用
我的总结
这个题目应该是不假的,我自己看了6个多小时。理论上一天差不多可以理解性地看一遍perl基础,但是不要妄想看完这个就可以看别人写的脚本了,那中间还隔着自己练习、代码出错的一大步
学习感受: 这次的学习感觉出知识迭代了。如果你之前没有接触过,可能真的需要一整天的时间来入门;如果之前零零散散接触过一些,再看一遍印象会增加一些