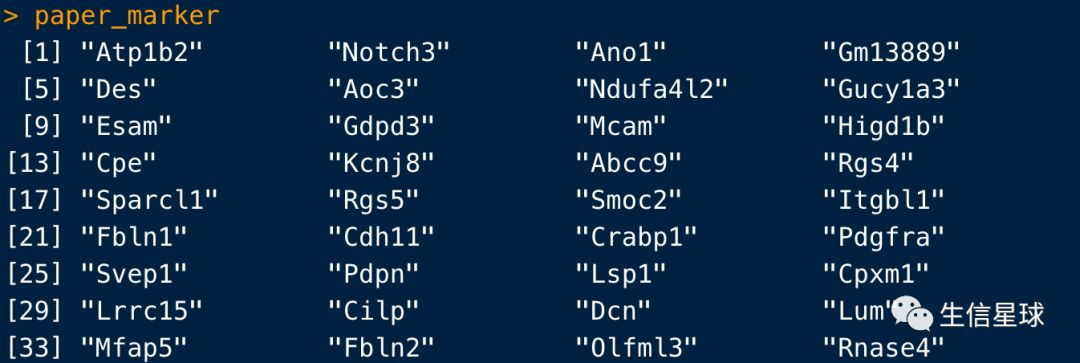
133-小技巧—怎样将文章图表的基因名放到R中?
刘小泽写于19.8.21
需求来源
我想从文章(例如:DOI: 10.1038/s41467-018-07582-3)中得到一些基因名,有几十个吧,但不想自己一个一个手动敲到R中,怎么办?
就像这张截图中的基因名,我想复制右边的那些基因名到R中

步骤一 复制
鼠标复制(前提是pdf中的图片可以选择文字)后粘贴到R中:
# 因为基因数太多,这里就不全展示了,只展示一部分
tmp <- c('Atp1b2 Notch3 Ano1 Gm13889 Des
Aoc3
Ndu fa4l2 Gucy1a3
Esam
Gdpd3
Mcam
Higd1b
Cpe
...')
步骤二 清理
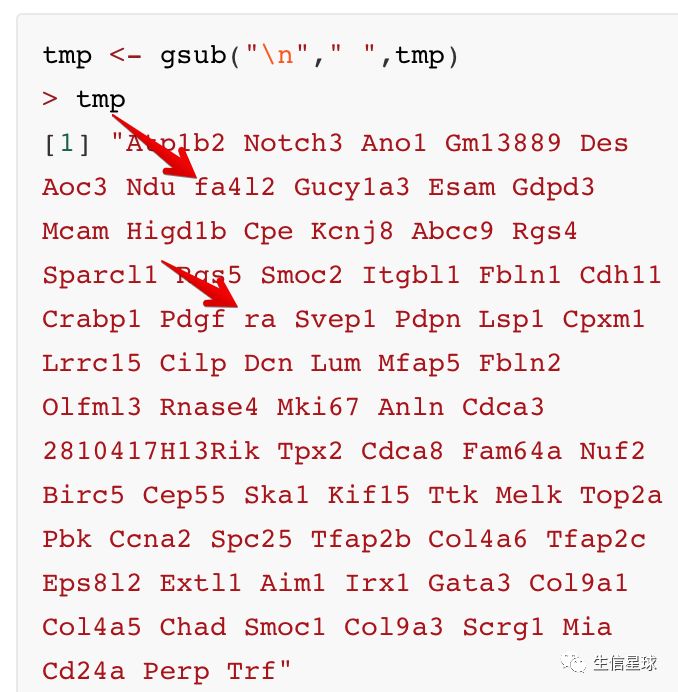
从文章直接粘贴过来的基因名,虽然可能名称不会错,但存在换行符的问题,可能粘贴过来会是这样:
# 出现了一大片换行符\n
> tmp
[1] "Atp1b2 Notch3 Ano1 Gm13889 Des\nAoc3\nNdu fa4l2 Gucy1a3\nEsam\nGdpd3\nMcam\nHigd1b\nCpe\nKcnj8\nAbcc9\nRgs4\nSparcl1\nRgs5\nSmoc2\nItgbl1\nFbln1\nCdh11\nCrabp1\nPdgf ra\nSvep1\nPdpn\nLsp1\nCpxm1\nLrrc15\nCilp\nDcn\nLum\nMfap5\nFbln2\nOlfml3\nRnase4\nMki67\nAnln\nCdca3 2810417H13Rik Tpx2\nCdca8\nFam64a\nNuf2\nBirc5\nCep55\nSka1\nKif15\nTtk\nMelk\nTop2a\nPbk\nCcna2\nSpc25\nTfap2b\nCol4a6\nTfap2c\nEps8l2\nExtl1\nAim1\nIrx1\nGata3\nCol9a1\nCol4a5\nChad\nSmoc1\nCol9a3\nScrg1\nMia\nCd24a\nPerp\nTrf"
那么就需要先将换行符换成空格
tmp <- gsub("\n"," ",tmp)
> tmp
[1] "Atp1b2 Notch3 Ano1 Gm13889 Des Aoc3 Ndu fa4l2 Gucy1a3 Esam Gdpd3 Mcam Higd1b Cpe Kcnj8 Abcc9 Rgs4 Sparcl1 Rgs5 Smoc2 Itgbl1 Fbln1 Cdh11 Crabp1 Pdgf ra Svep1 Pdpn Lsp1 Cpxm1 Lrrc15 Cilp Dcn Lum Mfap5 Fbln2 Olfml3 Rnase4 Mki67 Anln Cdca3 2810417H13Rik Tpx2 Cdca8 Fam64a Nuf2 Birc5 Cep55 Ska1 Kif15 Ttk Melk Top2a Pbk Ccna2 Spc25 Tfap2b Col4a6 Tfap2c Eps8l2 Extl1 Aim1 Irx1 Gata3 Col9a1 Col4a5 Chad Smoc1 Col9a3 Scrg1 Mia Cd24a Perp Trf"
步骤三 分割
现在得到了一个大的字符串,但是我们想要其中一个个的基因名小字符串,就用str_split分割
library(stringr)
paper_marker <- as.character(str_split(tmp,' ',simplify = T))
第四步 检查错误
为了复制粘贴的严谨,需要检查错误,不过先不用一个一个肉眼去看,可以用代码先检查一下:
# 先看看长度
> length(paper_marker)
[1] 74
发现不对,原文只有4组*18=72个基因,这里多了两个,应该是复制粘贴过来出现基因名内分裂导致的
因为这篇文章使用的小鼠基因名都是首字母大写,于是先找到基因名首字母不是大写的,再将它们替换掉
其中一个就是Ndufa4l2:本来是一个,但是粘贴过来成了两个:Ndu,fa4l2
# 先将分裂的基因名都换成原来的基因名(有重复先不管,最后一起去重)
paper_marker_1 <- str_replace(paper_marker,c('Ndu','fa4l2'),"Ndufa4l2")
# 然后每次都要检查
setdiff(paper_marker_1,paper_marker)
[1] "Ndufa4l2"
# 说明改过来了
另一个就是Pdgf 和ra
paper_marker_2 <- str_replace(paper_marker_1,c('Pdgf','ra'),"Pdgfra")
# 每次修改都要检查:
setdiff(paper_marker_2,paper_marker_1)
[1] "CPdgfrabp1" "Pdgfra"
# 这里看到修改之后又新出现了一个不同的基因"CPdgfrabp1",说明它是由于替换了一个简单的字符"ra",所以原来的"Crabp1"也被替换了,修改回来即可
paper_marker_2[paper_marker_2=='CPdgfrabp1'] <- 'Crabp1'
最后去重
paper_marker <- unique(paper_marker_2)
> length(paper_marker)
[1] 72
打完收工
找篇文章练练手吧~