209-bedGraph转bigwig一行命令竟然还能报错
刘小泽写于2020.10.19
0 前言
今天准备复现一张图,https://www-nature-com.libezproxy.um.edu.mo/articles/s41586-018-0350-5/figures/1
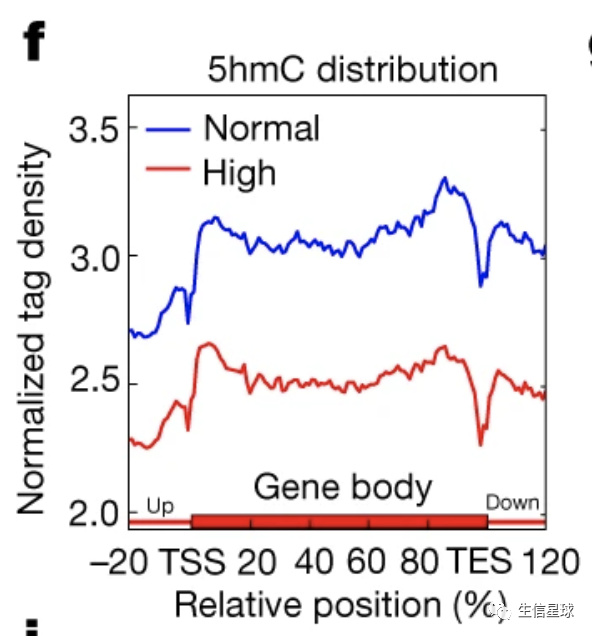
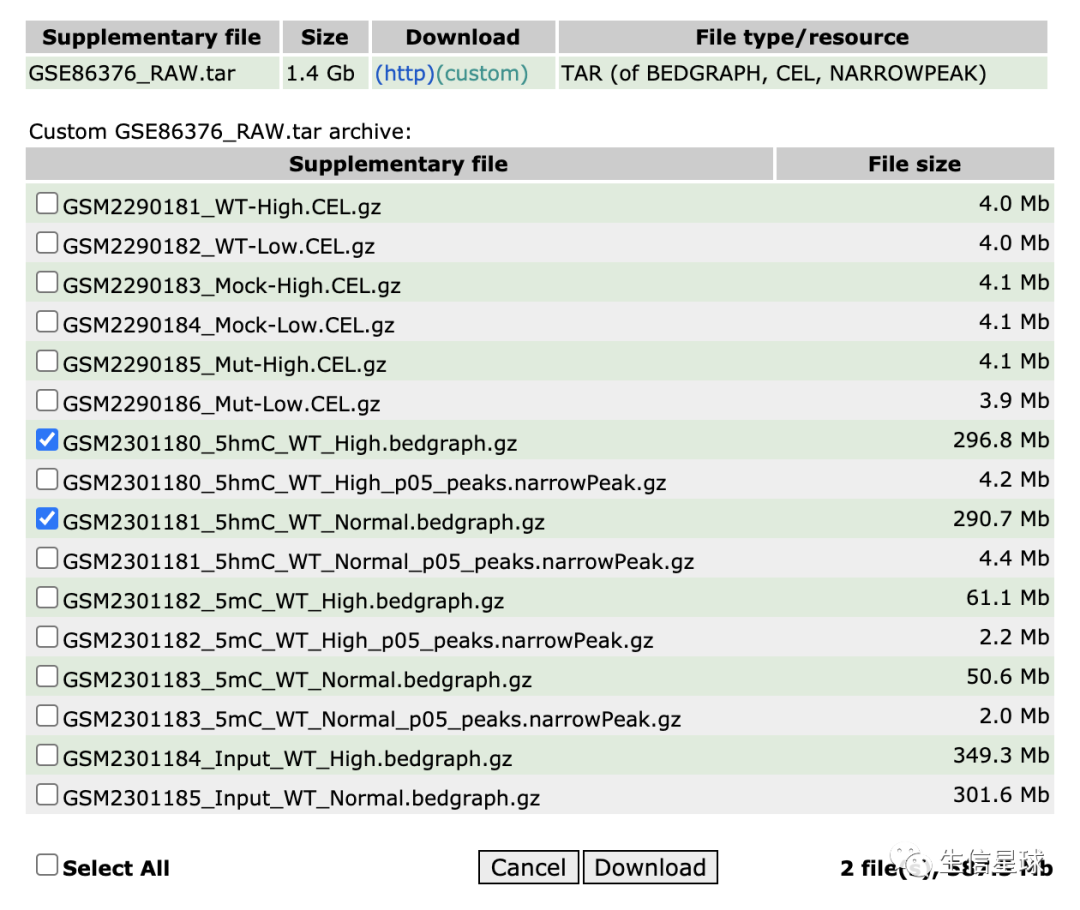
使用到的数据主要就是信号值,一般存储在bigwig中,但是看到文章给到的数据只有bedGraph,数据在: GSE86376
下载这两个就可以了:
然后运行下面命令即可
# first install bedgraphtobigwig
conda install -y ucsc-bedgraphtobigwig ucsc-fetchchromsizes
# get chrom.sizes
fetchChromSizes hg19 > hg19.chrom.sizes
# bedgraph to bigwig
for i in `ls *bedgraph`
do
(head -n 1 $i && tail -n +2 $i | sort -k1,1 -k2,2n | awk '{print $1,$2,$3,$4}' OFS="\t" ) > $i.sort &&
bedGraphToBigWig $i.sort hg19.chrom.sizes $i.bw
done
但是,在将bedGraph转换为bw文件时出现了报错:
End coordinate 81195241 bigger than chr17 size of 81195210 line 21756982 of GSM2301181_5hmC_WT_Normal.bedgraph.sort
哪里出错检查哪里,主要看看是不是bedgraph的坐标超出了真实的染色体大小
# 看看hg19.chrom.sizes中的chr17到底多大
grep chr17 hg19.chrom.sizes
chr17 81195210
# 看看bedgraph中的chr17最大是多少
grep chr17 GSM2301181_5hmC_WT_Normal.bedgraph.new.sort | tail -n5
chr17 81195010 81195013 3.42
chr17 81195013 81195023 2.73
chr17 81195023 81195106 2.05
chr17 81195106 81195119 1.37
chr17 81195119 81195241 0.68
# 果然,最后一行的终止坐标为81195241,对应上了报错信息,81195241超出了标准的hg19坐标范围,为什么呢?
1 背景:关于bedGraph与bigwig
是UCSC定义的格式,主要用来记录全基因组数据的每个坐标区间的测序深度、覆盖度
BedGraph definition: https://genome.ucsc.edu/goldenpath/help/bedgraph.html
bedgraph格式用窗口的方式代替原始的每个碱基的测序深度,主要包括两部分:
track line:
track type=bedGraphdata line:记录每个窗口内的测序深度信息。第二列和第三列列出了窗口的起始和终止位置,第四列是该窗口内的测序深度
可以利用bedtools的
-bg参数得到:bedtools genomecov -ibam input.bam -bg > depth.bedgraph例如:
# 注意其中只有name和description可以自定义填写 track type=bedGraph name="BedGraph Format" description="BedGraph format" visibility=full color=200,100,0 altColor=0,100,200 priority=20 chr19 49302000 49302300 -1.0 chr19 49302300 49302600 -0.75 chr19 49302600 49302900 -0.50 chr19 49302900 49303200 -0.25 chr19 49303200 49303500 0.0 chr19 49303500 49303800 0.25 chr19 49303800 49304100 0.50 chr19 49304100 49304400 0.75 chr19 49304400 49304700 1.00
BigWig (bw) definition: https://genome.ucsc.edu/goldenpath/help/bigWig.html
bw是wiggle的二进制格式。下面看看wiggle的内容,它也包含了track和data两部分(https://genome.ucsc.edu/goldenpath/help/wiggle.html):
track内容:
track type=wiggle_0data部分:有2种形式,并且其中的数值可以是整数,实数,正数或者负数
fixedStep,数据部分只有一列
fixedStep chrom=chr3 start=400601 step=100 11 22 33 # 表示 :values 11, 22, and 33 as single-base regions on chromosome 3 at positions 400601, 400701, and 400801, respectively. # 或者用span将含有相同value的连续碱基合并在一起 fixedStep chrom=chr3 start=400601 step=100 span=5 11 22 33 # 其中:step指定步长,span指定窗口的长度 # 表示:values 11, 22, and 33 to be displayed as 5-base regions on chromosome 3 at positions 400601-400605, 400701-400705, and 400801-400805, respectivelyvariableStep,数据有两列
variableStep chrom=chr2 span=5 300701 12.5 # 它的信息和下面👇是一样的 variableStep chrom=chr2 300701 12.5 300702 12.5 300703 12.5 300704 12.5 300705 12.5 # 二者都表示chr2的300701-300705区域上在基因组浏览器上的信号值是12.5
当然,wig可以转为bw:
wigToBigWig input.wig chrom.sizes myBigWig.bw
2 那么之前的问题出在哪?
之前为什么在将bedGraph转换为bw文件时出现了报错?
探索一 猜想
我首先怀疑是不是基因组坐标的问题,于是又下载了hg38的坐标
fetchChromSizes hg38 > hg38.genome.sizes
grep chr17 hg38.genome.size
chr17 83257441
看似这个chr17的问题解决了,于是再次运行
bedGraphToBigWig GSM2301181_5hmC_WT_Normal.bedgraph.new.sort hg38.genome.size test.bw
# 又一次给我弹出了报错,只不过这次换成了chr1
# End coordinate 249058980 bigger than chr1 size of 248956422 line 5556894 of GSM2301181_5hmC_WT_Normal.bedgraph.new.sort
因此,我感觉应该不是基因组版本的问题,依然是坐标的不对应
探索二 搜索
其实简单就能得到答案:https://www.biostars.org/p/269061/
其中有人提到:
the reads get extended past the end of the chromosome as part of MACS analyses. Plus MACS doesn't know which reference genome you've actually aligned your reads to, nor does it care
推测这个GEO中的bedGraph可能不是由bam直接得到的,而是利用macs2分析的结果得到的。比如使用命令:
macs2 -t $TRT -c $CTRL -g hs -n $NAME -f BAM -B -q 0.05 # -B outputs in bedgraph
而我们一般是怎么生成bedGraph呢?很多时候是利用deeptools的bamCoverage命令,同时还做了标准化处理(https://deeptools.readthedocs.io/en/2.1.0/content/tools/bamCoverage.html)
# 前面要经过align=》sort=》remove duplicate
bamCoverage -b ${sample}_rm.bam -o bw/${sample}.rpkm.bw \
--normalizeUsing RPKM -p 4
需要注意的是,这里的RPKM和转录组的标准化RPKM不太一样。虽然两个领域的normailize 都主要考虑各个样本的测序深度差异。这里的RPKM中的K指的就不是基因长度了,而是bin大小(默认50bp),每个bin是基因组上一个窗口,我们滑动它统计其中的reads数。因此公式是:
RPKM (per bin) = number of reads per bin / ( number of mapped reads (in millions) * bin length (kb)不过,M都是指的不同样本文库大小
在macs2的分析过程中,是不理会基因组上染色体的大小的,它会自己进行延伸,于是它的结果可能会超过边界。

3 怎么解决?
来自:https://www.biostars.org/p/199556/
# 还是要准备好基因组染色体大小
fetchChromSizes hg19>hg19.chrom.sizes
# 第一步
bedtools slop -i GSM2301180_5hmC_WT_High.bedgraph -g hg19.chrom.sizes -b 0 | bedClip stdin hg19.chrom.sizes GSM2301180_5hmC_WT_High.clip
# 第二步
sort -k1,1 -k2,2n GSM2301180_5hmC_WT_High.clip >GSM2301180_5hmC_WT_High.sort.clip
# 第三步
bedGraphToBigWig GSM2301180_5hmC_WT_High.sort.clip hg19.chrom.sizes GSM2301180_5hmC_WT_High.bw
