027-一个差异基因软件引发的问题
刘小泽写于18.8.25
今天在想找一下DESeq2怎么做火山图,然后找到了biostar教程,记得上面有关于RNA的章节,看到一个地方我不由停住了,教程中对deseq1和deseq2作了这样的评价:“deseq1 makes fewer mistakes but also finds fewer of the differentially expressed genes. That means it has a low FP and higher FN”, “In contrast the deseq2 and edgeR methods find more of the differentially expressed genes but at the cost of also producing more fasle values. They have higher TP and but also higherFP”
这里的FP、TP是什么意思?为什么TP高就好像很厉害,FP高就感觉不太开心呢?
简单查了一下,FP、TP出现在敏感性与特异性的范围中,维基百科搜索Sensitivity and specificity,就会出现

当然,这里的解释还是看不太懂,但是大概是这样
| True Positives(TP) 真阳性 | correctly identified 正确接受 |
|---|---|
| False Positives(FP) 假阳性 | incorrectly identified 错误接受 |
| True Negatives(TN) 真隐性 | correctly rejected 正确拒绝 |
| False Negatives(FN) 假阴性 | incorrectly rejected 错误拒绝 |
**嗯!翻译的不错!但还是不懂!**看来只有例子才能拯救对统计学的理解
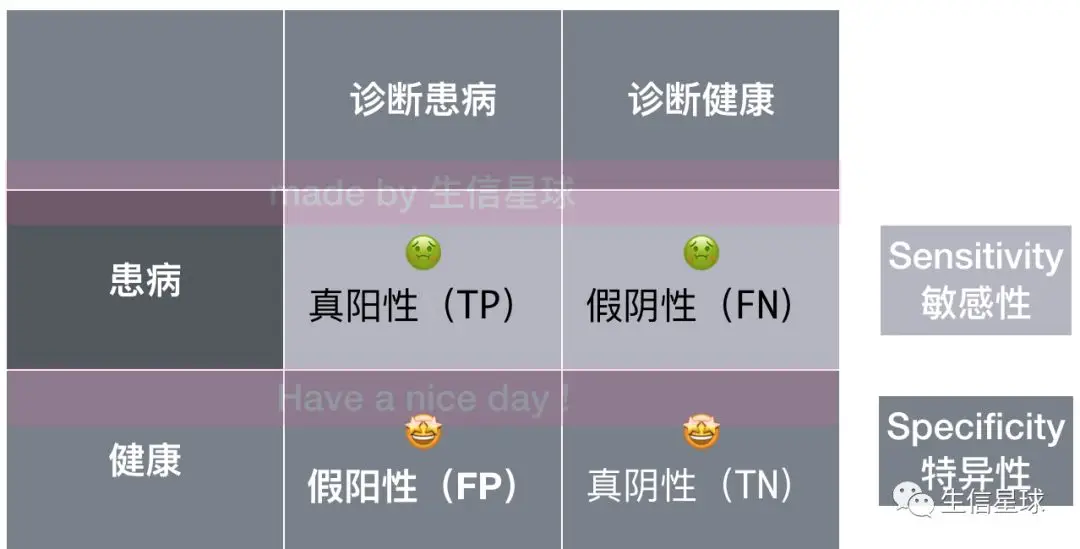
- 真阳性(TP):这人患病并且正确诊断为没病【需要这样的结果】
- 假阳性(FP):这人没病但被错误诊断为有病
- 真阴性(TN):这人没病并且正确诊断为没病【需要这样的结果】
- 假阴性(FN):这人有病但但被错误诊断为没病
敏感性有个计算公式:Sentitivity= TP/(TP+FN)
特异性 :Specificity = TN / (TN+FP)
再来一个例子

如何判断一个人是否是高血压呢?假如判断曲线如上图所示,正常人和高血压患者的判断范围完全不重合,就十分容易判断了**(以虚线为界即可)**
但事实上…二者是有重叠区域的,这是怎么制定高血压的标准?

如果标准线是左边橙色的虚线,那么凡是橙色左边的都是正常人;而橙色右边的都是高血压(注意:包括了本来就是高血压的和原来正常但血压偏高的部分人群)
这样就是设置了敏感性最高,不放过任何一个高血压的人以及疑似高血压的人,这时那部分疑似高血压的人就是被误诊的,假阳性率就是他们产生的
如果标准线是右边蓝色的虚线,那么凡事蓝色右边的都是高血压;而蓝色左边的判断都是正常人(但是这里同时包含了一部分血压相对较低的患者)
这样就是设置了特异性最高,也就是说,(虚线右侧)检测出来的百分百是高血压患者,从中不会冤枉任何人;但是(左侧)却有一部分高血压患者也被纳入非高血压的队伍,这就产生了假阴性率
因此,一般判断时会把标准线画在中间,这样兼顾了敏感性和特异性,能降低假阳性率和假阴性率
有的病早期症状比较明显,但一旦漏查就很危险(如:梅毒),因此可以把灵敏度调高,不放过任何一个真正或者可能患病的人;
有的病确诊费用高、预后情况不是很严重,但是误诊对患者影响比较大的,就要谨慎判断,这时可以提高特异性,只要没有病的人,绝不让他花冤枉钱
最后,可以简单记住:敏感性高=漏诊率低,特异性高=误诊率低
好了,这样就不难理解,差异基因分析软件deseq1存在低FP、高FN的问题,就是他为了出错更少,因此他工作也不积极(找到的差异基因就少);
deseq2和edgeR存在高TP、高FP的问题,也就是干活多(找到差异基因多),但同时出错也多
十全十美的软件不存在的,只能看自身的需求,软件选择如同人生,每个人活法都不同,但都希望能统筹兼顾~