006-从0开始-Linux学习笔记
刘小泽写于18.6.24 我相信这是比测序的世界更浩大的工程,但值得写出来!
计算机体系结构:
相信你对计算机的大体构造有所了解了,电路板、电线还有一些硬件,这是必需品
数据格式二进制 : 计算机是个电子设备,它的数字来源在于控制线路通电与否; 采用二进制相对于十进制更精确,能够方便控制电路板上的电流,有电代表数字1,无电代表数字0; 想想,如果采用十进制,怎样精确控制电流的强弱来表示0-9呢?那会很麻烦!
CPU包括运算器和控制器 【相当于工厂的工人和总监】
运算器– 工人(装货):通常是加法器、逻辑运算器
加法器:加减乘除运算都使用加法器完成; 加法器使用加数与被加数(这些数据都在存储器中获取); 【一般来讲,每个加法器只能进行一位加法运算,例如3位数的加法至少有3个加法器。 那么如果要计算32位的加法,就会有32个加数和32个被加数; 他们各需要32根线来进行运算,这势必很臃肿!那么如何解决?】
~ 这里引入了线路复用 ,可以同时传输指令、加数、被加数,很高效。但有两个问题
Q1. 如何识别指令和数据呢? A1. 靠的就是CPU上的控制位,数值1为指令,0为数据。
Q2. 如果刚传进来加数,想再传被加数,那么电路板上的电压就会调整为被加数的,之前的加数如果不存放起来,就消失了,怎么办? A2. 只需将前一个数据存放在寄存器
控制器– 总监(调配):协调运算器到存储器哪个存储单元读取数据,另外运算完还要靠它去找存储器中还有什么空闲位置存放数据
存储器RAM:【相当于工厂的仓库,有进有出】 就是内存,每一个存储单元在全局上有唯一的地址;
程序是由指定+数据构成的,而指令和数据都存储在存储器中,控制器要在存储器中获取控制指令,靠一根电线:指令/控制总线; 【出厂的时候内存条中什么也没有,那么我们需要将执行的程序放到存储器中去,需要一个外围设备,辅助用户先存储一些指令和数据】
缺点:断电丢失数据。所以需要一个外置设备保存数据或者用显示器显示出来
I/O设备 : 外围/辅助设备(键盘、鼠标、硬盘、显示器、网卡) 中断interrupt:硬件通知机制。比如敲一下键盘,电信号会传输到CPU,告诉CPU停下手头的工作,过来看看发生了什么。所以任何的硬件发生了改动,哪怕很小就像敲一下键盘,都会产生一次interrupt。因此,中断越多,CPU的效率越低~ 【但是,当一次中断发生时,CPU怎么知道是键盘还是鼠标发生的改变呢?】 【CPU的针脚和中断控制器相连~控制器上有多根线,每根线表示一个设备。 但是如果外部设备非常多时怎么办?比如一个服务器连了500块硬盘,那么是不是需要500根线呢? 并不科学!控制器的一根线上可以同时标示多个不同设备,也有点线路复用的意思】
其他一些概念:
北桥: 直接连CPU,高速总线控制器,快速实现数据交换。
南桥: 离CPU远,低速,连接外围设备。所有外围设备通过南桥汇总后,由同一根线连接到北桥,由北桥再转给CPU 【我们现在打开的网页都是存储在web服务器上的文件,相信你一定遇到过打开网页很卡,长时间加载不出来的情况~有没有想过是为什么?】 【**原因不难理解:**我们日常上网的流程就是:网页文件内容存储在web服务器硬盘,访问时需要先通过南桥再汇总到北桥,再交由CPU处理给网卡,发给各个用户。假如一个界面有2M,同时100万人访问,南桥连接的硬盘是支撑不了的,就会卡顿,严重会报废;那么你可能会想:为什么刷淘宝这么流畅? 一个原因可能是,你的手机争抢网速比较给力,把阿里web服务器分配的有限的名额抢到手就能访问; 另一个原因就是:为了避免高峰时段用户访问过多,南桥效率低下的问题,服务商会使用固态硬盘和北桥直接连接。当然,如果使用的是机械硬盘,南桥北桥差别不大,因为都很慢!】
主频: 前面说到,数据的输入是利用电信号的识别,也就是扳开关。有电为1,没电为0。扳一次开关为1Hz,那么我们平时所说的CPU主频2.9GHz,意思就是一秒能扳2.9 x 10^9^ 次,也就能有这么多次的数据变换
CPU与内存主频关系:
CPU主频(以GHz为单位)要高于内存(以MHz为单位),也就是说,比如CPU一次可以处理十个数据,但内存一次就能提供一个数据。那么CPU的强大会因为内存被拖慢。但是呢,目前升级CPU容易,升级内存主频成本会相当高。
其实人生就是在不断的妥协、权衡和放弃当中,来追求最大化的幸福,计算机亦如此
利用 缓存 解决这个问题,它就是一个折中。你可能听过一级、二级、三级缓存;级别越小,距离CPU距离越近,速度就越快。 缓存原则–> 程序局部性原理: 时间局部性:刚访问过的再次访问会快 空间局部性:距离访问过的数据存储位置近的访问快
低级 vs 高级语言: 低级语言:微码(汇编语言,人能识别但机器不能,因为很低层所以难学)–>编译器(机器能理解,转换为机器语言)–> 机器语言(0,1代码;二进制)
高级语言(汇编语言的上一级;兼具人类思考习惯和机器识别特性): 要先转换为汇编再转换为对应芯片上的机器语言,需要额外机制(API - application program interface。不同CPU用汇编语言写的有相同功能的程序,使用API虚拟相同的执行环境)来满足不同机器上运行同一个程序。
多任务处理:
- 交叉进行;
- 切分CPU与内存
CPU:按照时间顺序划分为多个time slice( 比如两个任务,第一个5ms第二个5ms,然后反复交替) 内存:按照任务数分段机制(第一段和第二段,有着相对的地址); 对于32位系统,最多使用2^32^ = 4G物理内存;64位系统,2^64^ 基本无上限
- 如何指定哪个任务该做什么呢?指挥官就是——操作系统。负责一个程序的启动、终止和回收,程序的切换等工作。【运行的程序称为“进程”】
内核: Kernel
通过 System call 系统调用来实现统一接口。操作系统(Windows, Mac, Linux)就是种内核。 【系统调用处于底层,相当于买馒头给了你一袋子小麦,利用起来比较麻烦,需要磨面、发面等,但是能做的事情很多,不止能做馒头,还能做包子面条】 功能:
- 进程管理
- 内存管理
- 提供文件系统
- 提供网络功能
- 提供硬件驱动
- 提供安全机制
库: API
任何程序执行都需要一个执行入口。库也是一堆程序集合,他是可执行程序,但是它没有执行入口,因此不能直接执行,只能等其他程序调用时才执行,执行的时候又可以提供一个统一的调用机制(call)。 有了操作系统(内核)以后任何程序都不能直接和硬件打交道,必须要通过操作系统(内核)来进行协调。但由于系统调用过于底层,就将其再次封装起来,使其功能更加强大(直接给你馒头,不需要自己将小麦加工成面粉),这种更高级的接口就是库(API,application program interface)。 所以程序员写程序直接通过库来写就行,调用其功能来开发程序(没必要“造轮子”)。利用不同内核的库编的程序,由于库的内部细节不同,一般不能跨平台运行,但如果调用接口相同,就能运行。
- windows下dll(Dynamic Link Library)动态链接库
- linux下.so(Shared Object)共享对象
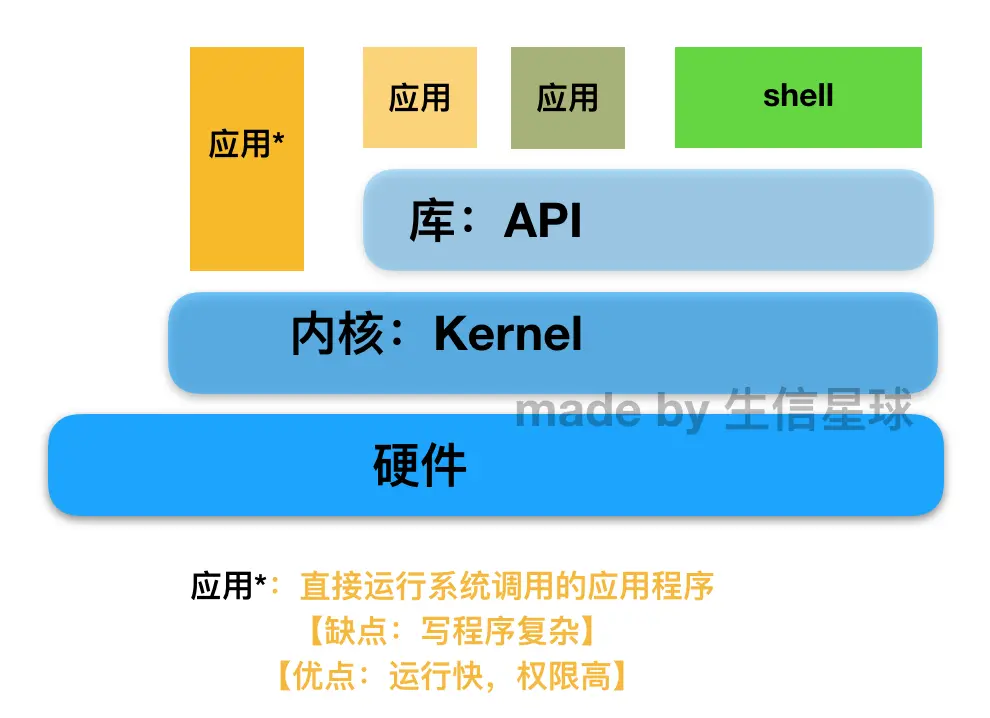
要跑起来一个程序,只需要提供三个东西:内核、程序依赖的库、shell 所以说,操作系统并不复杂,这三样最简单的只需要2M或3M空间就够了 【补充一下:应用程序放在硬盘上叫程序,但启动起来叫进程process】 要做一个web服务器,你只需要提供程序和它依赖的库就能行 那么你会想,为什么日常装的操作系统这么大,十几个G? 有各种文件,作为对这个主线的补充;为了提供图形界面,会装很多图片
开机启动的模式:
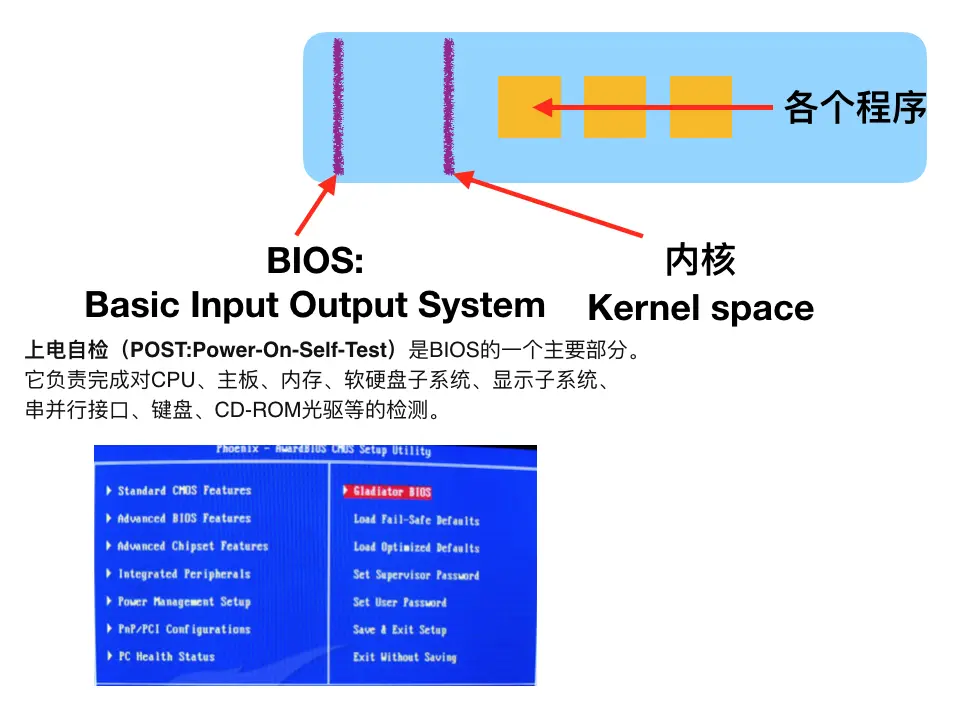
启动程序的方式:
- 随开机一起启动,称为“后台服务”
- 按需求启动,手动启动,称为“交互式程序”
**shell:**人机交互接口【下面会有更详细介绍】 用户与系统(内核)进行交互 分为:
- GUI( graphic user interface) 可视化 Gnome: C 开发; KDE: C++; XFace:嵌入式轻量系统
- CLI( command line interface) 命令行:效率更高! sh,bash(最广泛,开源),csh,zsh,ksh,tcsh等
以上是计算机必备的硬件软件,下面介绍linux 必备常识
发展历史:
早期Unix,后来收费–> 荷兰教授Andrew: 仿照Unix,开发Minix(在欧洲教学)
–> 【芬兰赫尔辛基 Linus:Linux之父 】+ 【Stallman:倡导软件自由获取、修改、学习,创办GNU运动, (有意思的递归式缩写GNU is Not Unix),提出GPL协议(General Public License) 。研发了很多优秀产品:Emacs:文本编辑器; gcc: GNU C Complier C语言编译器】
–> Linux只是个内核,它本身不是应用程序。它的库(API)是glibc,一个C库。利用glibc和gcc能移植其他软件,比如bash
–> 完整的系统应被称作GNU/Linux,因为GNU提供了必备的软件 –> 无论linux还是GNU,他们都是源代码,使用C开发的程序
–> 要想运行起来,必须编译成二进制(0、1代码)
–> 自己操作很复杂,所以诞生了一些团队将源代码linux在通用平台上编译、打包成可直接执行的二进制程序
–> 1991年的SLS、1992年的德国研究人员开发的Debian (他妻子名字Deb开头,他的名字ian结尾,比较感人了)、1993年的redhat、还有德国的SUSE【他们都被称为发行商release】其实他们内核一样,软件一样,可能只是配置文件不一样,加入了自己的logo,调整的参数等等
–> 开始打包的发行本包括了2万多软件,有些臃肿,又不便于软件管理,所以想要寻求一款软件管理工具
–> Debian开发了dpt (debian package tools)的工具; redhat模仿Debian开发了rpm(redhat package manager)。这样就能实现软件查询、安装、升级、卸载、校验等功能
–>后来redhat虽然给了编译好的二进制版本,但是有些后期补丁不放出来,而且虽然不像微软赚版权费,但它赚服务费,交的钱越多,它帮你解决问题修复漏洞速度越快
–> 有组织看不下去,他叫CentOS (Community enterprise OS, 旨在社区共享、开放),除了不提供服务保障,其他和redhat都一样 ,算是redhat的二次发行版本
–> redhat主要针对企业,后来出来了针对个人的Fedora, 更新速度很快,基本每6个月就会更新,测试稳定后又引入redhat。Fedora其实就是为企业版提供测试开发的。
–> Debian没有专业公司维护,入门比较难用,适合高阶用户;redhat/ CentOS在国内、北美很流行;SUSE在欧洲较流行
–> 基于Debian也开发了二次发行版本Ubuntu,适用于PC机 –> 基于Ubuntu又开发了它的二次发行版Mint,界面更加好看

Linux发展版本:
Linux是内核,内核是有版本的。91年是0.1,94年是1.0,然后几个著名的版本2.0, 2.2, 2.4, 2.6,3.0, 最新的是4.17.2。 发行版本:例如Ubuntu 16.04.4 , CentOS 7。他们的核心都是linux 4.0+
Linux的哲学思想:
- 由目的单一的小程序组成;组合小程序完成复杂任务
- 一切皆文件
- 尽量避免和用户交互,中间不需要输入任何内容
- 配置文件 /etc 保存为纯文件格式
- 能简写绝不写全称
Linux登陆login:
切换用户: 半切换:使得切换完还保留root –> su (switch user) 完全切换:su -l user 退出切换: exit
换密码:passwd 密码存放在影子口令中: 用户:/etc/shadow
account: 登录名 encrypted password: 加密的密码
组:/etc/gshadow
【只需了解】加密方法:
- 对称加密:加密和解密使用同一个密码
- 公钥加密:每个密码都成对儿出现,一个为私钥(secret key),一个为公钥(public key)。公钥加密,私钥解密
- 单向加密,散列加密:提取数据特征码,常用于数据完整性校验 1.不可逆 2.雪崩效应,一个字符的不一样,特征码就有很大不同,防破解 3.定长输出: MD5:Message Digest(信息摘要), 128位定长输出 【了解:加密:md5sum file ; 解密校验:md5sum -c file】 SHA1:Secure Hash Algorithm(安全哈希算法), 160位定长输出
用户管理的几个层级:
用户名:用户ID,可以被查找 【root用户创建新用户名:使用useradd 】
认证机制:Authentication,识别某个人就是它声称的那个人,比如密码
【前两个用于登陆】
授权:Authorization, 例如经理比普通员工享有某些特殊权限
审计:Audition (生成日志log)防止特权用户滥用权限
权限: 有九位,对应属主(u)、属组(g)、其他组(o)的权限 对于文件: r: 可读,使用类似cat等命令查看文件内容 w:可写,可以编辑或删除 x:可执行,eXecutable,可在命令提示符下当作命令提交给内核运行 对于目录: r:可对此目录进行 ls 操作列出内部所有文件 w:可以创建文件,但能否删除还要看具体文件 x:可使用cd切换进此目录,也可以 ls -l 查看内部文件详细信息 【默认一般文件不建议对外开执行权限,但目录可以】
Linux命令(Command):
命令提示符:prompt 登陆成功后显示的东西【#:root用户;$:普通用户 】
命令格式: 命令 选项 参数 命令: shell传递给内核,并由内核判断该程序是否有执行权限,以及是否能执行,从什么时候开始执行。(任何一个程序想要执行,必须要有执行入口) 例如: ls 是命令, -a、-l是短选项
选项:( options,用来修改命令的执行方式)
短选项: -character,多个选项可以组合 ,可以写ls -l -a 或者 ls -la 长选项: –word,不能组合,要分开 参数:(arguments) 命令作用对象【!多个参数要用空格隔开】命令类型
- 内置命令(shell builtin 内置)
- 外部命令:某个路径下有一个与命令名称相应的可执行文件
命令执行
魔数:magic number 用于标示二进制程序的执行格式 Windows和linux执行的魔数是不同的,所以说即使二者的C语言库一致, linux上编译的程序也未必能在windows上运行。 比如,写脚本时第一行总要加上
#! /bin/bash之类的外部命令的快速执行需要环境变量: 它是内存上划分出的一块空间,用于命名 用于定义当前用户的工作环境
printenv就能看到当前的环境环境变量包括什么? PATH、HISTORY、SHELL等【注意都要大些】 查看时统一使用echo $
其中有个PATH分管程序:它是使用冒号分割的路径。 当执行程序时,会按次序从PATH下一个个去找,直到第一次找到为止。以后如果再次使用,就不再从头找,会把第一次找到的路径放进缓存直接调用。 【
hash就相当于bash自带的缓存,记录了登陆之后使用的所有命令路径,告诉你哪个 命令hits命中多少次 **CACHE IS KING!缓存为王!**hash因为有索引,比一般的路径搜索快了不止万倍】
常用命令:
ls【list】列出所有指定路径下的子目录或文件
目录 & 路径 文件夹/目录也是文件,只不过比较特殊,是一种路径映射文件 路径:绝对路径 :从根向下找 相对路径: 相对于当前位置
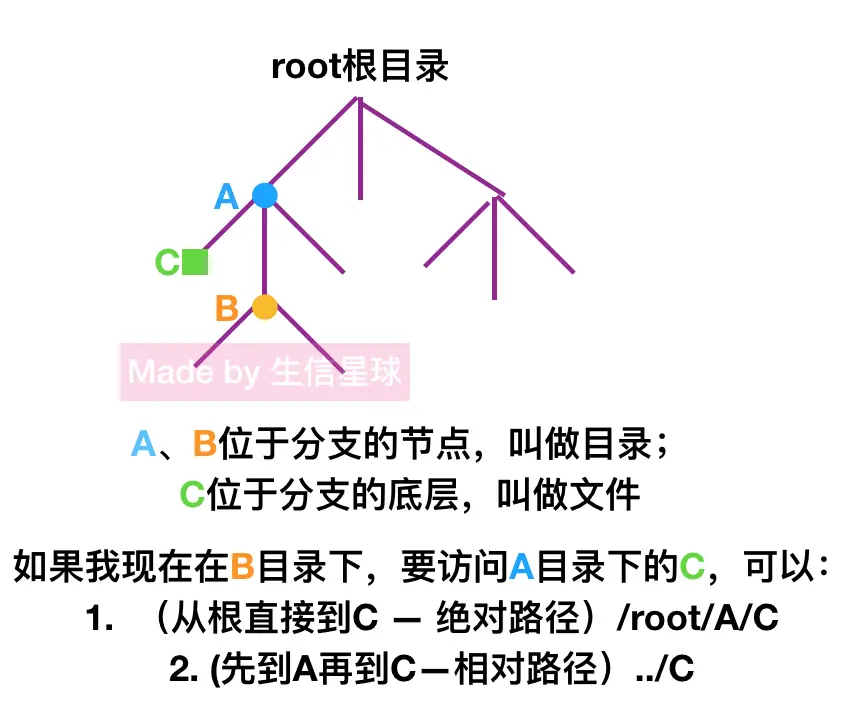
登陆系统后每时每刻都在目录中,working directory
pwd打印当前路径各个选项
-l 显示结果:一共7列 第一列有十位: 第一位为文件类型: -:普通文件(f,file) d:目录文件 b:块设备文件(block) c:字符设备文件(character) p:命令管道(pipe) s:套接字文件(socket) l:符号链接文件(symbolic link file) 后九位为文件权限(mode): 每3位一组,每一组:rwx(读,写,执行)没有则“-” 之后6列分别为: 文件硬链接次数 文件的属主(owner) 文件的属组(group) 文件大小(size):默认单位是字节 时间戳(timestamp):最近一次被修改的时间。 可分为: 访问时间(access); 修改时间(modify):改变内容; 改变时间(change):改变文件的属性数据(即元数据) 文件名 -h:human-readable 显示方式更易读 -a:显示以 . 开头的隐藏文件,包括. (当前目录) ,..(父目录) -A:显示以 . 开头的隐藏文件,不包括. (当前目录) ,..(父目录) -d:显示目录自身属性 -i:显示索引节点号 index node(iNode) -r:逆序显示文件(本来按照的是字母顺序) -R:递归(recursive)显示,即子目录内容也显示
cdchange directory
~ 表示为home directory
. 是当前所在的目录,.. 表示上一层目录。
cd - 前一个目录和当前目录之间来回切换,就像电视机快速换台
type显示指定命令属于内部还是外部命令
- alias:别名
- keyword:关键字,Shell保留字
- function:函数,Shell函数
- builtin:内建命令,Shell内建命令
- file:文件,磁盘文件,外部命令
- unfound:没有找到
echoshell编程中极为常用, 输出字符串或者打印变量的值
# 使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\b 删除前一个字符;
\c 最后不加上换行符号;【效果等于echo -n】
\n 换行;
\r 光标移至行首,但不换行;
\t 插入横向tab;
\v 插入纵向tab;
\\ 插入\字符;
printf默认不打印换行符,需要换行加 \nwhich查找并显示给定命令的绝对路径file查看命令/文件格式
命令帮助:
内部命令:help COMMAND
外部命令: COMMAND –help 或者man 或 info
man 手册信息
分章节 共8个 man number COMMAND 显示哪个章节
1.用户命令(/bin, /usr/bin, /usr/local/bin);2.系统调用; 3. 库调用;4. 特殊文件(设备文件[块设备、字符设备]) ; 5. 文件格式(解释配置文件语法); 6.游戏;7.杂项(Miscellaneous); 8.管理命令(/sbin, /usr/sbin/, /usr/local/sbin)
如何查看命令在哪个章节? –>whatis COMMAND
章节内容包括
- :表示可选
- |:表示多选
- <>:表示必选
- …:表示可以使用多次
- { }:表示分组
- NAME:命令名称及功能简要说明
- SYNOPSIS:用法说明,包括可用的选项
- DESCRIPTION:命令功能的详尽说明,可能包括每一个选项的意义
- OPTIONS:说明每一个选项的意义
- FILES:此命令相关的配置文件
- BUGS
- EXAMPLES:使用示例
- SEE ALSO:另外参照
翻屏
- 向后翻一屏:SPACE
- 向前翻一屏:b
- 向后翻一行:ENTER
- 向前翻一行:k
查找
- /KEYWORD:自前向后找
- ?KEYWORD:自后向前找
- n: 下一个
- N: 上一个
介绍目录与文件
Linux 文件系统:
根文件系统 rootfs
ls / 查看
/boot:系统启动相关文件,如内核,initrd,以及grub(BootLoader)
/dev:设备文件 —
体现了LInux的“一切皆文件”思想- 块设备:随机访问,数据块(如:硬盘)
- 字符设备:线性访问,字符为单位(有次序,例如键盘/鼠标/显示器)
设备文件没有大小,只有设备号,分为主和次设备号 主设备号:标示设备类型 次设备号:标示同一类型的不同设备
/etc : 配置文件。大多数为纯文本文件
/home:用户的家目录
/root:管理员的家目录
/lib:公共库文件(不能单独执行, 只能被调用) /lib/modeles:内核模块文件。 静态库:后缀.a,程序中包含库,直接移植程序就可以~静态编译 动态/共享库:后缀.dso,要移植程序的话,必须连同.so一起~共享节约资源
/media:挂载点目录,挂载移动设备(如U盘)
/mnt: 挂载额外的临时文件(如第二块硬盘)
/opt:可选目录(现在基本没用)
/proc:伪文件系统,内核映射文件,系统启动后才出现文件, 关机就空
/sys:伪文件系统,跟硬件设备相关的属性映射文件,关机就空
/tmp:临时文件,/var/tmp是另一个临时文件目录 【所有用户都可以操作,但只能删自己的,不能删别人的】
/var:可变化的文件
/bin:(binary) 可执行文件,用户命令
/sbin:管理命令
/bin、/sbin都是可执行程序,运行时依赖的库都放在/lib下,配置文件放在/etc
/usr:(universal shared readonly,只读文件)
/usr下也有/bin,/sbin,/lib,与系统提供基本功能相关; 根目录下的/bin,/sbin,/lib与系统启动相关,必需的; /usr/local:/bin,/sbin,/lib,第三方软件存放路径,非必需
目录命名规则:
- 严格区分大小写
- 不能使用
/当文件名 - 长度不能超过255个字符
目录管理:
ls 、cd 、 pwd、
mkdir(在mnt/test/文件夹下创建x和y文件夹,x文件夹下创建m文件:
mkdir -pv mnt/test/{x/m,y})【命令行展开{}下面会有介绍】
tree 查看目录树
rmdir 删除空目录
文件管理:
touch:通过改时间戳来创建新的空文件,可连续创建
stat:用于显示文件的属性/状态信息。能看到那三个时间戳 [访问、更改、改变]。
cp: 复制一个文件到一个文件 cp SRC(source) DEST(destination);
或多个文件到一个目录cp {file1, 2,3} /dir/ –> 花括号展开机制
-r/R:递归复制整个目录
-p:保留源文件或目录的属性;
-d:当复制链接文件时,把指向的文件一并复制。简而言之,保持链接
-a:(= -dpR) 保留所有原始属性,比-p保留的更多,常用于备份目录或文件;
rm: -f 强行删除;-i 删除前提示; -r 递归删除 mv: -t 可以先写目标地址DEST,再写源SRC; -b:当文件存在时,覆盖前,为其创建一个备份<备份模式>;
install 只能复制文件,不能复制目录(复制时比cp功能少) -d: 创建目录【与mkdir -p类似】 -t: 与mv命令一样,可以先写目标目录,后写文件 -m,–mode=模式:自行设定权限模式 (像chmod),而不是rwxr-xr- 参考: chmod -g,–group=组:自行设定所属组,而不是进程目前的所属组
任何具有竞争力的行业,大部分优秀的工程师的成长道路都是这三种境界:
- “昨夜西风凋碧色,独上高楼,望尽天涯路” – 站在一定角度,看别人,定目标;
- “衣带渐宽终不悔,为伊消得人憔悴”– 为第一重境界的目标努力 【大概需要一到两年,这个领域内胜过很多人,此前不是很明白的东西也可以游刃有余地操作。但是会遇到一个天花板,再想往上走很困难 ~ 称为“业余专家”】
- “众里寻她千百度,蓦然回首,那人却在,灯火阑珊处” 【坚持五年以上成为“权威”; 十年如一日,“Expert”】
定一个小目标: 自己从头组装起来Linux系统,学习LFS,完成后就可以深度掌握Linux。新手至少需要两天时间,所有的库、软件都要自己搜索源代码进行编译。【为何要从头开始?一是通过LFS学会Linux的全部内容,之后遇到什么问题都能知道问题来源;二是通过源代码编译,相比于拿来就用的二进制,会提高系统性能。因为不同硬件平台编译的结果是不同的,虽然有时都能用,但早期编译的版本不能运行新硬件的新功能】

文本查看:【只用于文本!不要用来打开二进制文件😯】
cat、tac、more、less、head、tail
cat -n(number):显示行号;
-E : 显示每行的结尾【对于Linux,文本文件的行结束符是$ ; Windows是$和Enter。因此从Linux复制文本文件到Windows,统统显示为一行。就是缺少了回车或者换行符】
tac 反向显示cat
more/less : 分屏显示
head /tail: 默认显示十行,-n 自定义行数; tail -f:查看文件尾部,不退出,等待显示后续追加至此文件的新内容 【用途:监控web服务器中哪个用户正在访问哪个网页】
文本处理:
先讲下数据库的格式: 信息很多,有意义的数据在于我们怎么抽取 比如,我们要描述一个人,有时只需要他的身高体重,有时只需抽取年龄性别
常见的表格,又称二维表,关系型数据库的一种: 一个表可以没有行,但不能没有列
cut 用来分割字段
-d (delimiter)指定分隔符, 默认tab。【不需要空格,直接加分隔符即可】
-f 显示第几个字段
-f 1,3 显示第1和第3个
-f 1-3 显示第1-3个
例如 cut -d: -f1 /etc/passwd 就抽取了这个文件的第一列
sort 默认根据ASCII表中的顺序升序排序 -n : 按照数值大小排序 -r :(reverse) 降序排序 -t : 指定字段分隔符 【等同于cut的-d】 -k:指定字段【等同于cut -f】 -u: 不管是否相邻,只要重复,行就显示一次 -f: 排序时忽略字符大小写
uniq 【与sort不同。在它看来,只有相邻的重复行才算做重复行。所以常与sort连用】 -c: 每列旁边显示该行重复出现的次数 -d: 仅显示重复出现的行列 (一个代表) -D: 显示所有的重复行列 (全部)
wc word count 文本统计 结果依次显示为:行数、单词数、字节数 -l:只显示行数 -w: 只显示单词数 -c: 显示字节 -L: 最长的一行包含了多少个字符
tr 字符转换或删除 translate or delete characters
例如: tr ‘ab’ ‘AB’ 引号中的叫做字符集 这样就把包含字符集a、b的文件对应替换为A、B 但是tr不能直接加文件,如果想对一个文件中字符进行替换 使用输入重定向
<:tr 'ab' 'AB' < /etc/passwd
将所有小写都换成大写:tr ‘a-z’ ‘A-Z’
-d : 删除出现在字符集中的所有字符 如: tr -d ‘ab’
文件查找:
**locate:**非实时,模糊匹配,查找是根据全系统文件数据库进行的
updatedb:手动生成文件数据库- 优势:速度快
find: 实时,精确,遍历,支持多查找标准
使用:
find 查找路径 查找标准 查找后的处理- 查找路径:默认当前目录
- 查找标准: 默认指定路径下的所有文件
- 查找后处理:默认为打印
匹配标准:
-name ‘FILENAME’: 对文件名作精确匹配
文件名通配:
*任意长度的任意字符 ? []
-iname 文件名匹配不区分大小写
-regex PATTERN 基于正则表达式查找
-user USERNAME 根据属主查找 【同理-group】
-type 根据文件类型查找
-size 根据文件大小
组合条件:-a 与【默认】 -o或 -not非
例如:寻找当前目录下,不属于user1,也不属于user2的文件:
find ./ -not \( -uer user1 -o -user user2\)
压缩、解压、归档:
压缩格式:
gz,bz2,xz,zip,z,最常用前三种
- gzip: .gz
压缩完成后会删除源文件;不能压缩目录 -$:1-9: 设定压缩比,默认是6 -d = gunzip gunzip: 解压完后也会删除压缩文件 zcat 查看.gz文本压缩文件中内容
- bzip2: bz2 比gzip压缩比更大
-k:保留压缩源文件 bunzip2 : 解压 bzcat:查看.bz2文本压缩文件
- xz : .xz
-k:压缩时保留原文件 unxz:解压 xzcat 查看.xz文本压缩文件
- zip:既归档又压缩的工具
zip filename.zip file1 file2 …:压缩后不删除原文件 unzip filename.zip:解压,不删除原文件
归档工具:tar(只归档不压缩)
-c:创建归档文件 -f FILE.tar:操作的归档文件 -x:展开归档 --xattrs:归档时,保留文件的扩展属性信息 -t:不展开归档,直接查看归档了哪些文件 -zcf:归档并调用gzip压缩 -zxf:调用gzip解压缩并展开归档,-z选项可省略 -jcf:归档并调用bzip2压缩 -jxf:调用bzip2解压缩并展开归档,-j选项可省略 -jtf:调用bzip2解压缩,不展开归档,直接查看归档了哪些文件,-j选项可省略 -Jcf:xz压缩 -Jxf:调用xz解压缩并展开归档,-z选项可省略
离用户最近的强大程序——bash
bash及其特性:
发展历史:
shell翻译为外壳,是用户连入计算机后进行交互式操作的程序 广义上shell包含两类: GUI:Gnome、KDE、Xface CLI:最早期bsh(近似B语言) –> csh(编程方式类似C语言), 大大促进Unix流行–>ksh(比csh更强大,但需要付费) –> linux流行后也需要一个shell, 出现了bash(born again shell),兼具了csh、ksh的各种特性,且更强大 –> 最新的zsh更丰富,但不是很流行
shell特点:
shell本身就是进程。可以新建多个shell,且互不冲突。
进程:在每个进程看来,当前主机上只存在内核和当前进程。名字可以相同,但进程号各自唯一,Linux只识别进程号【就像全国重名的人很多,但身份证没有重复】
shell作为一个程序、一个外部命令(相对于内核来讲)。作为程序就能运行内部命令,因此还能继续创建子shell。因此很多时候,对子shell的设定,对父shell无效;反之亦如此。
shell可以交互打开。例如当前打开的是bash,可以在bash中敲ksh,在ksh中又可以敲zsh…
bash特性
命令行编辑: 光标跳转: Ctrl+A:跳到命令行首 Ctrl+E:跳到命令行尾 Ctrl+U:删除光标至命令行首的内容 Ctrl+K:删除光标至命令行尾的内容 Ctrl+L:清屏
命令历史:history
删除:
-c : 清空全部历史
-d:删除指定位置【要删除指定位置向下n个,在-d后加n】
调用:
!n: 执行第n条命令!-n:执行倒数第n条 !!:执行上一条 !string: 执行命令历史中最近一个以指定字符串开头的命令
Esc松开后按 .: 引用上一个命令的最后一个参数【也可以!$】
命令补全: 输入的前几个字符是在PATH中能唯一识别的,敲一次tab就能打出来; 如果不能,敲两次tab会列出所有和输入字符相关的命令
命令别名alias:
bash只是一个程序,当前所有的设置将在退出这一个程序后失效
若要长期使用alias,可将相应的alias命令存放到bash的初始化文件
/etc/bashrc中方法:alias 别名='原命令 -选项/参数’
撤销:unalias 别名
\别名:适用于别名和原命令一样,只是添加了一些参数,现在想使用原命令
命令替换: 把$()中的子命令替换为前面命令的执行结果,举两个例子就能懂
例如要打印当前路径: echo “The current dir is $(pwd)” 例如要在当前目录下新建一个包含年月日时分秒的文件 touch ./file-$(date +%F-%H-%M-%S).txt
命令行展开
用命令行展开特性一步完成需要分开成多步完成的操作 使用
{}将相应的参数括起来,括号中的参数以逗号分隔, 例如:/tmp/{x,y} #生成/tmp/x和/tmp/y mkdir {1..5} #生成1-5为名的文件夹 mkdir -p {1..5}/{1..5} #在1-5的文件夹里再生成1-5的文件夹
文件名通配 globbing 快速匹配到你想要的文件
例如:touch a123 abc ab123 xyz x12 xyz123 新建这6个文件 目的:
找出a开头的文件:ls a* => a123 ab123 abc
【*:匹配任意长度的任意字符】
找出第二个字母是y的文件 ls ?y* => xyz xyz123
【?:任意单个字符】 【如果找第三个字母是y的,只需要 ??y* 】
以字母开头,数字结尾,中间不限
ls [a-zA-Z] * [0-9]
[ ]:匹配指定范围内的任意单个字符 [a-z], [A-Z], [0-9], [a-zA-Z] [^]:匹配指定范围之外的任意单个字符 [^0-9] 非数字 [^[:alpha]] 非大小写字母 [[:alpha:]]:大小写字母 = [a-zA-Z] [[:space:]]:空白字符 [[:punct:]]:标点符号 [[:lower:]]:小写字母 [[:upper:]]:大写字母 [[:digit:]]:数字 [[:alnum:]]:数字和大小写字母 = [a-zA-Z0-9] 【练习:】 【1. 创建如下文件:xi、jie6、u56m、my、m.r、t 94、8%u、567 注意:t 94文件中间有空格!
2. 显示以a或m开头的文件; 3. 显示文件名中包含数字的文件; 4. 显示以数字结尾且文件名中没有空白的文件; 5. 显示文件名中包含非字母或数字的特殊符号文件
Linux管理(大部分基于ROOT用户)
1. 背景知识:介绍用户和组
linux 无论识别用户还是进程,都会通过数字识别。 所以每一个用户或组都有一个ID,存储在各自数据库中
用户:UID,数据库/etc/passwd 用户类别:6位二进制共65536个 #管理员:0 $普通用户: 系统用户1-499 ; 一般用户:500-60000再后面很少用
【只需了解】用户信息:
例如:u1239:X:503:504:::/home/1239/:/bin/bash u1239 #用户名 X #x 表示密码,存放于 /etc/shadow 503 #用户id(0代表root、普通新建用户从500开始) 504 #基本组ID,额外组等信息在 /etc/group : #注释(多个注释逗号隔开) /home/u1239/ #家目录 /bin/bash #默认shell, 当前系统所有合法shell存放于:/etc/shells组:GID,数据库/etc/group
$私有组:创建用户时,如果没有为其指定所属的组,系统会自动为其创建一个与用户名同名的组 ;
$ 基本组:用户的默认组 ;
$ 附加组,额外组:默认组以外的其它组 【只需了解】组信息:
例如:vip:`$!$`:???:13801:0:99999:7:*:*: vip #组名 `$!$` #被加密的口令 13801 #创建日期与今天相隔的天数 0 #口令最短位数 99999 #用户口令 7 #到7天时提醒 * #禁用天数 * #过期天数
2. 管理用户:
添加用户 useradd
-u<uid>:指定用户id;< 默认uid要>=500,且其他用户没有使用>;同时创建私有组
【建立的帐号,保存在/etc/passwd文本文件中 --> tail -1查看最后一行】
-g<gid>: 指定基本组(必须事先存在)
-G<gid>: 指定附加组,可以有多个,用逗号隔开
-c: “COMMENT” 用户注释(注意要加引号)
-d:/path/to/somedir 指定家目录
例如:useradd -c "Tony" -d /home/bla uer2
=> 新建名叫Tony的user2,指定家目录在/home/bla
-s: 指定shell路径
-m -k: 在用户家目录下复制skel文件
skel文件是:bash基础结构文件 ls -a /etc/skel查看
包含.bashrc、.bash_logout、.profile三个基础文件
-M:不创建家目录
-r:添加系统用户(UID:1-499)
修改用户属性 usermod
-u UID
-g GID(必须是之前存在的)
-a -G GID 追加附加组,而不覆盖原来的(不加-a则之前存在的附加组将会被覆盖)
-c 修改注释
-d -m:指定新的家目录,并把之前家目录文件移动到新的家目录
-l : 修改登录名
-e : 指定过期时间YYYY-MM-DD
-L:锁定/禁用用户 -U:解锁
-s : 修改默认shell
修改默认shell :chsh [USERNAME] =>这种方法是交互式,不如usermod -s快
删除用户 userdel
-r: 同时删除用户的家目录,默认不会删除用户家目录
ID 查看用户账号相关属性信息 【普通用户也可以使用】
UID 是对一个用户的单一身份标识。组ID(GID)则对应多个UID.
一些程序可能需要UID/GID来运行。id使我们更加容易地找出用户的UID以GID而不必在/etc/group文件中搜寻
-u或--user :显示用户ID;
-g或--group:显示用户所属群组的ID;
-G或--groups:显示用户所属附加群组的ID;
-n或--name:显示用户,所属群组或附加群组的名称
finger 查找并显示用户信息 显示本地主机现在所有的用户的登陆信息,包括帐号名称,真实姓名,登入终端机,闲置时间,登入时间以及地址和电话
修改finger注释信息: chfn [USERNAME]
密码管理:
passwd [USERNAME] –stdin:采用标准输入方式修改密码 【利用管道将密码指定给这个命令,减少与用户的交互】 -n 最短使用 -x 最长使用
例如:echo ‘mykey’ | passwd –stdin user
-l : 锁定 -u:解锁 -d : 删除
pwck:验证系统密码/etc/passwd和/etc/shadow的内容和格式的完整性
3. 管理组:
创建组:groupadd -g GID -r 添加为系统组
修改组 :groupmod -g GID -n 修改组名
删除组 :groupdel 组加密:gpasswd 登陆新组:newgrp 【流程就是:1. 如果之前用户和这个新组没关系: ‘root下’ groupadd -> gpasswd -> ‘当前组下’ newgrp; 2.如果之前用户有一个附加组,现在想切换到附加组,直接newgrp】 切换后退出:exit
【练习:需要root权限】 1、创建一个用户thanos,其ID号是2018,基本组是marvel(组ID为2222),附加组为linux:
groupadd -g 2222 marvel groupadd linux useradd -u 2018 -g marvel -G linux thanos
2、创建一个用户steve, 其全名为Steve Rogers, 默认shell为tcsh:
useradd -c “Steve Rogers” -s /bin/tcsh steve
3、修改thanos的ID号为2020,基本组为linux,附加组为steve和marvel:
usermod -u 2020 -g linux -G steve, marvel thanos
4、给steve加密码,并设定密码最短使用期限为3天,最长30天:
passwd -n 3 -x 30 steve
5、将thanos的默认shell改为/bin/bash:
usermod -s /bin/bash steve 或者使用chsh steve
6、添加系统用户banner,且不允许它登陆系统:
useradd -r -s /sbin/nologin banner
4. 管理:
chown:改变文件/目录属主(只有管理员才能使用)
chown USENAME file
-R: 递归改变目录中的子目录/文件的属主
–reference=/path/to/somefile file1 : 把file1文件属主设定为和somefile一样
chown USENAME:或.GRPNAME file : 同时改变属主和属组
chgrp: 改变属组 –> 用法同chown
chmod: 修改文件权限 支持-R 以及 –reference 权限范围的表示法如下:
u User,即文件或目录的拥有者;
g Group,即文件或目录的所属群组;
o Other,除了文件或目录拥有者或所属群组之外,其他用户皆属于这个范围;
a All,即全部的用户,包含拥有者,所属群组以及其他用户;
r 读取权限,数字代号为“4”;
w 写入权限,数字代号为“2”;
x 执行或切换权限,数字代号为“1”;
- 不具任何权限,数字代号为“0”;
s 特殊功能说明:变更文件或目录的权限。
更改三类用户的权限
也就是说,如果权限是rwx,那就是4 + 2+ 1 =7 如果是-wx,就是 0 + 2 + 1 =3 chmod 733 file 表示对于属主满足rwx,对属组和其他组是-wx 如果要对整个文件夹设置权限,chmod +R 733 dir 采用数字的方式比识别rwx字母的速度快得多,推荐用数字 【三位数字少一位就从头补0,如:输入75,理解为075】
更改某一类用户的权限:
chmod a/u/g/o=MODE file 【这里mode只能用r、w、x,不能用数字】 也可以一次性改两个:e.g. chmod go=r file ; chmod g=rx,o= file
更改某类用户的某个或某些权限:
操作某个权限:e.g. chmod u+x,g-x file 全部用户都增加某一权限:chmod +x file 操作某些权限:chmod u-wx file
【特殊权限】 SUID:运行某程序时,相应进程的属主是程序文件自身的属主,不是启动者 开启这一项,意味着赋予用户临时对这个文件有了root权限 chmod u+s FILE / chmod u-s FILE 如果FILE本身原来就有执行权限,则SUID显示为s;否则为S
SGID : 与SUID原理相似
Sticky: 在一个公共目录,每个都可以创建文件,删除自己的文件,但不能删除别人的文件 chmod o+t DIR / chmod o-t DIR
同rwx,SUID、SGID、Sticky也对应4、2、1 假如更改权限时是这样:chmod 5755 file : 第一个5就对应4+1: SUID+Sticky
**【了解即可】**umask ** 新建文件权限的掩码 【四位数,只看后三位】 创建文件:初始值666- umask 创建目录:初始值777-umask 例如当前用户umask 为022,新建文件的权限将变为666 - 022 = 644 改变umask:直接定义新的值 umask Num 【文件默认不具有执行权限,若算得的结果中有执行权限,则将其权限加1】
【非必须掌握】属主、属组和权限位的关联?
当一个用户发起一个进程,它能访问的权限取决于这个进程的属主与被访问的文件的属主是否一致,一致就运行属主的权限(前三位); 不一致再看访问的属主和被访问的属组是否一致,一致就运行被访问的属组权限(中间三位); 若都不一致就运行其他组权限。 然后程序运行起来后,不管之前程序的属主是谁,现在就是该用户
只想让某个用户获得文件权限怎么办?
之前学了使用chmod +数字可以设定组内、其他组的访问权限,那么如果只想让组内或组外的某个成员看怎么办?
FACL:Filesystem Access Control List 帮助你 利用文件扩展保存额外的访问控制权限
setfacl -m:设定 -x:取消 u:UID:perm : 设定某某用户有什么权限(perm) g:GID:perm:设定某某组有什么权限(perm)
例如:setfacl -m u:u1239:rw inittab 就是将u1239这个用户赋予了inintab文件的rw属性getfacl:查看文件的fac
【练习:从头创建新用户[完全手动]–root用户下进行】
1、 新建一个没有家目录的用户bioplanet; –> 结果是该用户的属主、属组仍然为root
useradd -M bioplanet #每执行完一个命令要验证,比如这里怎么验证新添加了没有home的用户? #查找用户信息 – finger bioplanet #看看/home下有没有– ls /home – 现在/home下没有是正常的 #看看有没有用户id – id bioplanet
2、 复制/etc/skel 为 /home/bioplanet; —> 添加架构文件为了在/home下表现出来该用户
cp -r /etc/skel /home/bioplanet #验证下bioplanet的权限,以及复制成功没有 ls -l /home 看属主、属组是否为root ls -la /home/bioplanet 看三个架构文件是否生成
3、改变/home/bioplanet 及其内部文件的属主属组均为bioplanet;
chown -R bioplanet:bioplanet /home/bioplanet #ls -ld /home/bioplanet 验证
4、/home/bioplanet及其内部的文件,属组和其他用户没有任何访问权限
这里不能用:chmod -R 700 /home/bioplanet 因为700相当于也改变了属主 我们这里只需要改属组和其他,使用 chmod -R go= /home/bioplanet
5、su bioplanet 新建用户完成, 接下来还要改三样东西 设置基本组为bioplanet(5000),附加组为之前存在的mygroup
6、修改passwd:
vi /etc/passwd 最后一行添加:
bioplanet❌5000:5000::/home/bioplanet:/bin/bash
7、修改group:
vi /etc/group 最后一行添加:
bioplanet❌5000:, 另外找到mygroup,在后面添加上bioplanet
8、修改shadow
先看一下shadow的格式: 用户:密码:修改时间:密码最短使用期限:最长使用期限:警告时间::: 【修改时间time=(date +%s)/86400 】【后三项一般就是0:99999:7:::】
vi /etc/shadow
#一会设置密码,先用!!占位
bioplanet:!!:time:0:99999:7:::
自动设置密码:passwd 手动设置:
openssl passwd -1 -salt '12345678'再输入密码,就得到一串加密的密码 密码复制到刚编辑的shadow中, 把!!替换
5. 用户登陆:
bash的配置文件
按作用范围分类:
- 全局配置:
/etc/profile,/etc/profile.d/*.sh,/etc/bashrc - 个人配置:
~/.bash_profile,~/.bashrc【当全局和个人发生冲突时,以个人为准】
- 全局配置:
按功能分类:
profile类的文件: 设定环境变量 运行命令或脚本
bashrc类的文件:
设定本地变量 定义命令别名
在用户登陆角度看shell类型
登录式shell:
- 账号密码正常通过终端登录
- su - USERNAME
- su -l USERNAME
非登录式shell:
- su USERNAME
- 图形终端打开窗口
- 自动执行的shell脚本
配置文件读取顺序:
登录式shell
/etc/profile –> /etc/profile.d/*.sh –> ~/.bash_profile –> ~/.bashrc –> /etc/bashrc
非登录式shell
~/.bashrc –> /etc/bashrc –> /etc/profile.d/*.sh
Linux管道及I/O重定向:> < » «
意义: 数据运算结束后保存在内存中,但是关机以后的数据呢?要想长期保存运算结果,必须有一种机制传输到外部设备上,方便以后获取,这就是I/O的作用。 问题又来了: 从哪个设备读入数据或指令,将运算结果保存到什么地方或输出到什么地方去?
数据/指定来源:INPUT设备【键盘、鼠标、网卡】
放到哪里:OUTPUT设备【硬盘、显示器】
可能性很多,但是计算机不知道具体采用哪种,所以需要系统设定默认值:
默认输入设备: 标准输入, STDIN, 文件描述符0 –> 键盘 **默认输出设备:**标准输出, STDOUT,文件描述符1 – > 显示器 标准错误输出: STDERR, 描述符2 –> 显示器
I/O 重定向: ** 改变 输出或输入来源**的操作
>:覆盖输出,原有内容被覆盖;
>>:追加输出,保留原有内容,在尾部新增新内容;
set -C:禁止对已经存在文件使用覆盖重定向,若要强制覆盖输出,则使用 >|
set +C:关闭上述功能;
2>:只能重定向错误输出,不能输出标准输出;
2>>:追加,重定向错误输出;
&>:重定向标准输出或错误输出至同一个文件;
<:输入重定向;
<<:Here Document,在此处生成文档,后一般加 EOF(end of file) 或END,表示文档结束标记。
# cat >>/tmp/myfile.txt <<EOF
> The first line.
> The second line.
> EOF
#会提示你输入要追加的内容,直到输入EOF/END为止
#结果在 myfile.txt 文件的结尾追加EOF之前的两行内容(EOF 行不追加)。
输出重定向:COMMAND … > log 2>/log 输入重定向:一些命令不支持接文件,例如tr命令 tr ‘a-z’ ‘A-Z’ < file
#计算器重定向,一行命令输出结果【bc为计算器】 bc «< “scale=2;111/44” =>精度为2位小数,计算111/44
输出重定向有一个位置:/dev/null【设备目录下,但是为空】 bit bucket【数据黑洞,一旦输出到这里则不会输出】
管道 : 前一个命令的 输出,作为后一个命令的 输入 命令1 | 命令2 | 命令3 | …
体现了Linux的哲学思想之一:组合小命令完成复杂任务
例如: cut -d: -f1 /etc/passwd | sort | tr ‘a-z’ ‘A-Z’ #用户名排完序,再大写 再如:#只想统计/etc/passwd的行数,不显示行数后的信息
#如果采取wc -l /etc/passwd , 会得到 307 /etc/passwd, 我只要第一列因此 wc -l /etc/passwd | cut -d ' ' -f1 => 注意指定空白分隔符
管道小程序之 tee ,结合它会把数据重定向到给定文件和屏幕上
echo ‘Hello world’ | tee /tmp/print.out #将echo的内容通过tee,一份打印到屏幕上,一份保存到print.out中
【练习:】
1、 统计/usr/bin/目录下的文件个数:
ls /usr/bin | wc -l
2、取出当前系统上所有用户的shell, 要求每种shell只显示一次,并按顺序显示
cut -d: -f7 /etc/passwd | sort -u
3、如何显示/var/log目录下每个文件的内容类型
file /var/log/* 或者先进入/var/log再使用反引号(位于ESC键下方) file ‘ls /var/log’
4、取出/etc/passwd 文件的前6行
head -6 /etc/passwd | tail -1
5、取出/etc/passwd文件中倒数第9个用户的用户名和shell, 显示到屏幕上并且保存到/tmp/中
head -9 /etc/passwd | tail -1| cut -d: -f1,7 | tee /tmp
6、显示/etc目录下所有以pa开头的文件,并统计其个数
ls -d /etc/pa* | wc -l
7、不使用文本编辑器,设定clear的简写cls,立刻生效
printf ‘alias cls = clear’ » ~/.bashrc source ~/.bashrc
文本处理:
grep:
根据模式搜索文字,并将符合模式的文本行显示【部分匹配就可以】
使用:grep [options] PATTERN [file]
[options]:
-i 忽略字符大小写的差别
--color 用颜色突出显示匹配的字符
-v 反转查找,显示没有被模式匹配到的行
-o 只显示匹配到的字符串
-n 显示行号
-E 使用扩展正则表达式
-A #:显示前面#行
-B #:显示后面#行
-C #:显示前后#行
模式(PATTERN):文本字符或正则表达式的元字符组合成的匹配条件
正则表达式:regular expression,REGEXP
- 基本表达式:Basic REGEXP
元字符:
.任意单个字符[]指定范围内的任意单个字符[^]范围外的任意单个字符字符集:使用时要再用[]框起来 [:digit:],[:lower:],[:upper:],[:punct:], [:space:], [:alpha:],[:alnum:]
匹配次数(贪婪模式:尽可能长地去匹配):
*匹配前面的字符任意次如:a,b,ab, aab, acb,adb,asdb中用a*b表示的 只有b,ab,aab
.*匹配任意长度的任意字符\?匹配前面的字符1次或0次\{m,n\}匹配前面的字符,最少m次,最多n次\{1,\}表示最少一次,多了不限位置锚定:
^锚定行首,后面的字符必须在行首出现$锚定行尾,之前出现的字符必须出现在行尾^$空白行\< 或 \b锚定词首:其后面的任意字符必须作为单词开头出现\> 或 \b锚定词尾:其前面的任意字符必须作为单词结尾出现例如:
\<root\>表示搜索整个单词root; 也可以 \broot\b分组:就是使用括号,只不过需要加转义符
\(\)例如:
\(ab\)*就是匹配一个或多个ab整体后向引用:后面引用前面搜索到的内容
\1,\2,\3...比如:要寻找开头是某个数字,中间可能有多个字符,结尾还是这个数字的:
grep '\([0-9]\).*\1$' \etc\passwd
- 扩展表达式:Extende REGEXP
egrep = grep -E
字符匹配:
.、[]、[^]与基本表达式相同次数匹配:
*匹配前边字符任意次?【扩展表达式的一个优点就是:不需要反斜线】匹配0次或1次+匹配其前面字符至少一次【=基本表达式中的\{1,\}】{m,n}位置锚定==等同于基本表达式中
分组: () 、 \1, \2, \3…
或者:
|表示Or例如C|cat表示匹配:C 或 cat 如果想表示Cat 或 cat ,使用分组:(C|c)at
小成: 想找出ifconfig文件中1-255的数字:
ifconfig | egrep '\b([0-9]|[0-9][0-9]|1[0-9][0-9]|2[0-5][0-5])\b'进阶: 找出ifconfig文件中的ip地址: ip地址格式是:4个0-255的数字,中间用.分割ifconfig | egrep '(\b([0-9]|[0-9][0-9]|1[0-9][0-9]|2[0-5][0-5])\b\.){3}\b([0-9]|[0-9][0-9]|1[0-9][0-9]|2[0-5][0-5])\b' -o3. fgrep: fast快速搜索【不支持正则表达式】
Sed(String editor):
背景知识:
行编辑器,逐行读取 –sed 【全屏编辑器–vim】
处理模式:把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),将行与模式相比较,如果符合模式接着这段内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。【注意:】默认不编辑源文件,仅对模式空间中的副本作处理
使用方法:
sed [options] 'AddressCommand' file...
[options]: -n: 只显示经过处理的行,保存在模式空间的未处理行不显示 -i : 直接修改源文件【慎用!】 -e SCRIPT -e SCRIPT…:同时执行多个SCRIPT脚本 -f /PATH/TO/SED_SCRIPT: 后接实现保存好的脚本合集,相当于-e的组合版 -r : 使用拓展正则表达式
Address:
StartLine, EndLine
e.g. 1,100 $:最后一行
$-1 : 倒数第二行/RegExp/
e.g. /^root/ 表示以root开头的行
/pattern1/, /pattern2/
第一次被pattern1匹配到的行开始,到第一次被pattern2匹配到的行结束
LineNumber – 指定的行
StartLine, +N
从startline开始,向后N行
n~m : 从n开始的每m行
Command:
d:删除符合条件的行 p: 显示符合条件的行 a \string: 在指定的行后面追加新行,内容为string \n可以换行,可以一次性多输出几行 i \string:在指定的行前面追加新行,内容为string r FILE: 将指定文件特定内容添加至某一行【 FILE为文件路径】 w FILE:将地址指定的范围内的行另存至新文件
s/pattern/string/修饰符: 查找pattern并替换为string 【默认只替换每行中第一次被模式匹配到的字符串】 【修饰符:g 全局替换; i: 查找时忽略大小写】
更好用的功能:s后面跟着的/可以换成其他的,比如###,@@@。 这个作用就是:避免符号冲突而转义
&: 特殊的后向引用模式,匹配整个串【也很好用】
e.g. 一段文字中的like和love,我要全部在后面加个r
sed `s/l..e/&r/g` sedtest.txt
& 不是万能的,有时必须用到后向引用
e.g. 还是上面的文字,将like和love中的l换成L #也就是把除了l的部分进行后向引用,只改变l–> L
sed 's/l\(..e\)/L\1/g' sedtest.txt
【小练习:】
1、删除test.txt文件中行首的空白符
sed -r ’s#^[[:space:]]+##g’ test.txt
2、删除test.txt文件中的空白行
sed ‘/^$/d’ test.txt
3、删除test.txt文件开头的#号
sed ’s/^#//g’ test.txt
Shell编程:
1. 基础知识:
人和机器交流需要语言,这种语言叫做编程语言,使用编译器或解释器让人机解读 编程语言:机器语言、汇编语言、高级语言
- **高级语言:**最接近人类的思维方式,相对容易学习;并且通过编译器也可以让机器理解
静态语言:编译型语言
有一个程序开发环境,不需要借助额外的二进制程序,就能直接写代码。写完代码后需要一个编译器,将其直接转换为二进制后可以独立运行
强类型语言(类型即变量类型):必须事先声明变量,可能还需要初始化 (数值为0,字符串为空
NULL)需要事先完全转换成可执行的二进制格式 C、C++、JAVA、C#
动态语言:解释型语言 弱类型语言:变量随用随声明*(默认为字符串)*
执行的时候再转换【有一个解释器,边解释边执行】 PHP、SHELL、python、perl
面向过程: Shell, C【linux就是基于C语言】 面向对象:JAVA,Python,perl【perl也面向过程】,C++
- 变量:明确的说变量是内存空间
首先数据存储在内存中,如果将所有待计算的数值都存在内存,内存肯定不够大。因此随着运算器运算,内存空间是不断变化的。比如要计算1加到1000,先存进来1,然后运算器拿走,接着把2放入内存空间,然后2被拿走… 所以这段内存空间是不断变化的,这就是变量
【了解即可】变量有两种类型:字符和数值(整型和浮点型) 为何要区分类型呢?=> 用于事先确定数据存储格式和长度,防止数据溢出
【逻辑运算】:与(&)、或、非(!) 1:真;0:假 短路逻辑运算: (1): 与:只要有一个为假,结果一定为假 (2): 或:只要有一个为真,结果一定为真
【 变量赋值】VAR_NAME=VALUE
【变量名称】只能包含字母、数字、下划线,且不能以数字开头; 不应该与系统中已有的变量重名; 最好做到见名知义
2. bash变量:
变量类型:本地变量(局部变量)、环境变量、位置变量、特殊变量
本地变量(局部变量)
本地: VARNAME=VALUE:【作用域为当前bash进程, 对子shell失效】; 引用变量:${VARNAME},不影响变量名时可以略去括号。 e.g. 定义animal=pig 分别输入三条命令,看看结果: 1. echo "there are some $animals" 2. echo "there are some ${animal}s" 3. echo 'there are some ${animal}s' 【单引号是强引用;双引号弱引用】 局部: local VARNAME=VALUE:作用域为当前代码段;环境变量:
作用域为:【当前shell进程及其子进程】。 脚本在执行时会启动一个子shell进程: 命令行中启动的脚本会继承当前shell环境变量; 系统自动执行的脚本(非命令行启动)就要定义需要的各环境变量 export VARNAME=VALUE “导出环境变量” VARNAME=VALUE export VARNAME位置变量:
$1, $2, ... #表示命令的第 1 个参数,第 2 个参数... shift:对于同一个$1,可以进行轮换【好比执行过的$1为老员工,他要退休,把位置让给年轻人,也就是下一个$1】;同时shift # 也可以同时shift多个特殊变量:
$? 上一个命令的执行状态返回值 【当数据被丢掉/dev/null中,没有返回结果时,可以用这个判断】 一般程序执行可能有两类返回值: 1. 程序执行结果 2. 程序状态返回代码(0-255) 0:正确执行--幸福 1-255:错误执行--不幸💔[1,2,127系统预留] 【应了一句名言:幸福的家庭都是相似的,不幸的家庭各有各的不幸】 $# 参数的个数 $* 参数列表 $@ 参数列表
撤销变量: 定义变量可以用set,set $VARNAME, 但是不用也行 撤销变量用unset VARNAME
查看shell中的变量 set – 包括了环境变量和本地变量 printenv / env / export – 查看环境变量
添加变量:(如添加环境变量)
#在环境变量后面添加变量 export PATH=$PATH:/usr/local/apache/bin #在环境变量前面添加变量 export PATH=/usr/local/apache/bin:$PATH
3.脚本:
什么是脚本? 命令的堆砌,按实际需要,结合命令流程控制机制实现的程序
魔数:shebang
#!/bin/bash #注释行不执行条件判断:【可以说是追求真值的过程】
命令间的逻辑关系:
逻辑与:&&【只为验证结果是否为真】 第一个条件为假,第二个条件不用再判断; 第一个条件为真,结果取决于第二个条件
逻辑或:||【只为验证结果是否为真】
第一个条件为假,第二个继续判断,有一个真就行; 第一个为真,则第二个不用再判断
例如:如果用户存在,就显示“用户存在”,否则添加: id user1 && echo “user exists” || useradd user1
进阶: 如果用户不存在,新建用户并且给他密码,否则显示存在 ! id user1 && useadd user1 && echo “user1” | passwd -stdin user1 || echo “user1 exists”
条件测试: 【整数、字符、文件测试】 测试表达式:【一定要有空格】
[ expression ] – 命令测试法
[[ expression ]] — 关键字测试法
test expression
例如:测试两个整数变量是否相等 INT1=66 INT2=77
[ $INT1 -eq $INT2 ][[ $INT1 -eq INT2 ]]set $INT1 -eq $INT2
整数测试:
[ expression ]:表达式两段必须要有空格 -eq:测试两个整数是否相等;比如 `$A -eq $`B; -ne:测试两个整数是否不等;不等,为真;相等,为假; -gt:[great than]测试一个数是否大于另一个数;大于,为真; -lt:[less than]测试一个数是否小于另一个数;小于,为真; -ge:大于或等于 -le:小于或等于例如:检查用户UID是否为0,为0就显示管理员,否则显示为普通 【注意:先定义变量,这样在整个脚本中都能重复使用】
#!/bin/bash NAME=user1 USERID=`id -u $NAME` [ $USERID -eq 0 ] && echo 'Admin' || echo 'Common'⚠️小Tip: 【反引号的意思是调取命令执行的结果; 不加反引号只是表明命令的运行状态,是成功,还是失败,如果只需要状态的话,那么命令结果对我们来讲就是无用信息,可以丢到/dev/null中】
文件测试:
-e FILE:测试文件是否存在;e.g. [ -e /etc/innitab ] -f FILE:测试文件是否为普通文件; -d FILE:测试指定路径是否为目录; -r FILE:测试当前用户对指定文件是否有读取权限; -w FILE:测试当前用户对指定文件是否有写入权限; -x FILE:测试当前用户对指定文件是否有执行权限;例如:给定一个文件,比如/etc/passwd,判断这个文件中是否有空白行;如果有,则显示其空白行数;否则,显示没有空白行。
#!/bin/bash #先判断这个文件是否存在,不存在就退出 FILE=/etc/passwd if [ ! -e $FILE ];then echo "No such file" exit 1 fi #存在再继续判断空白行 if grep "^$" $FILE &> /dev/null;then echo "Blank rows number is: `grep "^$" $FILE | wc -l`" else echo "No blank line" fi字符测试: 等值比较:
[ $A = $B ]不等值比较:[ $A != $B ]测试是否为空:-n 测试指定字符串是否不空:-z如何组合两个以上的条件? -a 与关系; -o:或关系; !非关系 e.g. 表示
1 <= $# <= 3: ``if [ $# -ge 1 -a $# -le 3]或者 ``if [ $# -ge 1] && [ $# -le 3]`
控制结构:
单分支if语句
#几个必须条件:必须有分号,必须有then,但是then可以另起一行,结尾必须是fi且单独一行 if 判断条件; then statement1 statement2 ... fi双分支if语句
if 判断条件; then statement1 statement2 ... else statement3 statement4 fi例如:判断当前系统上是否有用户的默认shell为bash; 如果有,就显示其中一个的用户名;否则,就显示没有这类用户 【借用/etc/passwd可以查看用户名、UID、GID、SHELL等】
#!/bin/bash #先看抓取‘结尾的bash’的状态结果是否为0,如果有bash,继续 #另外判断完后,这个信息不用输出,所以丢到/dev/null中 grep '/<bash$' /etc/passwd &> /dev/null RETVAL=$? #retval意思是‘返回值’ if [ $RETVAL -eq 0 ]; then #返回值为0,即正确,有结果 AUSER=`grep '\>bash$' /etc/passwd | head -1 | cut -d: -f1` #使用反引号``是赋给变量运行结果 echo "$AUSER does exist" #双引号弱引用 else echo "No such user" fi多分支if语句:
if 判断条件1; then statement1 ... elif 判断条件2; then statement2 ... elif 判断条件3; then statement3 ... else statement4 ... ficase 语句:号称比if多分枝更易懂的结构
case SWITCH in value1) statement ;; value2) statement ;; *) statement ;; esac
for循环:
for 变量 in 列表; do 循环体 done 遍历完成之后,退出; # 如何生成列表: 1. {1..100} 2. `seq [起始数 [步进长度]] 结束数` # 起始、步长可省略 e.g. seq 1 2 10 => 1 3 5 7 9 # 声明 SUM 是整型 declare -i SUM=0 [-x # 声明是环境变量] #计算从 1 加到 100 #!/bin/bash # declare -i SUM=0 for I in {1..100}; do #SUM=$[$SUM+$I] #或 SUM+=$I done echo "The sum is $SUM."e.g.1 for循环脚本,依次向/etc/passwd中的每个用户问好
#!/bin/bash # LINES=`wc -l /etc/passwd | cut -d' ' -f1` for i in `seq 1 $LINES`;do echo "Hello, `head -n $i /etc/passwd | tail -1 | cut -d: -f1`" donee.g.2 计算1000以内奇数之和、偶数之和:
#第一种写法 #!/bin/bash # declare -i ODDSUM=0 for i in `seq 1 2 1000`;do ODDSUM=$[$ODDSUM+$i] done echo "the sum of odd is:$ODDSUM" declare -i EVENSUM=0 for i in `seq 1 2 1000`;do EVENSUM=$[$EVENSUM+$i] done echo "the sum of even is:$EVENSUM" #第二种写法 #!/bin/bash # declare -i EVENSUM=0 declare -i ODDSUM=0 for I in {1..1000};do if [ $[$I%2] -eq 0];then let EVENSUM+=$I else let ODDSUM+=$I fi done echo"Odd sum is $ODDSUM" echo "Even sum is $EVENSUM"结果就是:the sum of odd is:250000 the sum of even is: 250500
while循环
适用于循环次数未知的情况
while CONDITION; do statement ... done例如:计算100以内所有正整数的和 #!/bin/bash declare -i I=1 declare -i SUM=0 while [ $I -le 100 ]; do SUM+=$I let I++ done echo $SUMShell中进行算术运算【前三种最为常见】
let 算术运算表达式
let C=$A+$B$ [算术运算表达式]
C=$[$A+$B]$((算术运算表达式))
C=$(($A+$B))expr 算术运算表达式, 表达式中各操作数及运算符之间要有空格,而且要使用命令引用
C=
expr $A + $B
随机数
echo $RANDOMRANDOM: 0-32768exit 提前结束脚本
exit # 状态值0代表执行成功,其他值代表执行失败。 如果脚本没有明确定义退出状态码,那么,最后执行的一条命令的退出码即为脚本的退出状态码(所以需要自己指定一个状态码,例如exit 1)
测试脚本是否有语法错误:
bash -n 脚本但是测试结果是模糊的,不能作为最终判断依据bash -x 脚本可以清楚看到脚本中哪个地方不符合我们预期, 对于大段脚本尤其适用!之前学过了变量的四种类型–> 本地变量(局部变量)、环境变量、位置变量、特殊变量
上面👆使用的主要有本地变量、特殊变量(
$?、$#). 位置变量如何在脚本中应用呢?位置变量最大的作用就是将命令后的各个参数引入进脚本, 化身成
$1, $2...这种 e.g. 给脚本传递两个参数(整数);显示此两者之和,之积#!/bin/bash #如果获取的参数不是两个,那么就退出不再进行 if [ $# -ne 2 ]; then echo "Usage:test.sh ARG1 ARG2 [...]" exit 1 fi #####以上就是使用命令时出现的使用帮助,就是这么来的##### #接下来如果是两个,就求和、求乘积【注意echo的弱引用】 echo "The sum is:$[$1+$2]." echo "The prod is:$[$1*$2]."
Vim编辑器:
Vi : Visual Interface; Vim: Vi Improved – 文本编辑器:编辑纯 ASCII 的文档,没有多余的修饰符 – vim是一种全屏编辑器,模式化编辑器
一、模式:
- 【默认】编辑模式(命令模式)—执行命令
- 输入模式—输入文本
- 末行模式—执行待定命令
模式切换
编辑模式–>输入模式:
i:在当前光标所在字符的前面,转为输入模式; a:在当前光标所在字符的后面,转为输入模式; o:在当前光标所在行的下方,新建一行,并转为输入模式;
I:在当前光标所在行的行首,转换为输入模式 A:在当前光标所在行的行尾,转换为输入模式 O:在当前光标所在行的上方,新建一行,并转为输入模式;
输入模式 –> 编辑模式
Esc编辑模式 – > 末行模式
:例如:
删除第10行,直接在
:后输入10d删除第10-12行,输入
10,12d设置行号:set nu
不退出使用shell:比如在vim中想查看/etc目录下文件
! ls /etc
二、文件打开与关闭
- 打开文件
vim +# file : 打开后直接处于第#行 vim + file : 打开后处于最后一行 vim + /PATTERN: 打开文件,定位到第一次被PATTERN匹配到的行首
- 关闭文件
# 1、末行模式关闭文件 :q 退出 :wq 保存并退出=:x :q! 不保存并退出 :w 保存 :w! 强行保存 # 只读文件, 只有管理员可以强行保存 # 2、编辑模式下退出 ZZ:保存并退出
三、移动光标
逐字符:
h:左 l:右 j:下 k:上 <数字>[h/j/k/l]:移动n个字符
逐个单词:
w:移至下一个单词的词首 e:跳至当前或下一个单词的词尾 b:跳至当前或前一个单词的词首 <数字>w:跳n个单词
行内跳转:
0:跳至绝对行首 ^:跳至行首的第一个非空白字符 $:跳至绝对行尾
行间挑战:
<数字n>G:跳转至第n行; G:跳至最后一行 末行模式下,直接给出行号,回车即可
四、翻屏
Ctrl+f:向下翻一屏 Ctrl+b:向上翻一屏 Ctrl+d:向下翻半屏 Ctrl+u:向上翻半屏
五、删除
删除单个字符
x:删除光标所在处的单个字符 <数字>x:删除光标所在处及向后的共n个字符
删除/剪切多个或整行
d命令可以跟跳转命令组合使用, 如:
dw, de, db, d$dd:删除当前光标所在行 <数字>dd:删除包括当前光标所在行在内的n行,然后跳到下一行;末行模式下: Start,End d
.表示当前行$最后一行$-n:倒数第n行+<数字>:向下的n行 删除的内容可以撤销,最后一次删除的内容可以粘贴g
先删除,再转为输入模式 —与d类似
修改命令(change) c –> 比如输入cc,那么整行删除然后直接可以输入
六、小操作
- 粘贴 p/P
p:如果删除或复制为整行内容,则粘贴至光标所在行的下方; 如果复制或删除的内容为非整行,则粘贴至光标所在字符的后面; P:如果删除或复制为整行内容,则粘贴至光标所在行的上方; 如果复制或删除的内容为非整行,则粘贴至光标所在字符的前面;
复制 y — 与d类似
替换
r : 替换单个字符,
[#]r<chr>r后面要接上替换的字符;前面[#]就是输入一个数字,表示将后面那个字符替换几次,可以不填 R: 一次实现多个替换撤销操作
u,可以按多次 如果多撤销了一次,可以还原上一次撤销ctr + r重复上一次操作
.可视化模式 v : 按字符选取
与shell交互
:! COMMAND
七、查找替换
查找
/PATTERN:从当前往后找 ?PATTERN:从当前往前找 n:往后跳转 N:往前跳转
查找并替换 在末行模式下使用s命令(和 sed 一样)
s /PATTERN / STRING / [g,i] g: 全局替换; i忽略大小写 。 二者可以同时使用 %: 表示全文查找、替换
# 例如:从当前行到倒数第二行,查找所有的小写sh替换成大写的SH : .,$-1s/sh/SH/g# 又如:将/etc/server.repo文件中的ftp://instructor.com/pub替换为http://172.16.0.1/yum 【这里的文件是虚拟的,只为演示】 # 这里有个小技巧,可以使用# @等符号代替/,这样就不用转义了 :%s#ftp://instructor.com/pub#http://172.16.0.1/yum#g
八、多文件处理 [熟练了会很常用]
1.使用VIM编辑多个文件
vim FILE1 FILE2 FILE3 :next 切换至下一个文件 :prev 切换至前一个文件 :last 切换至最后一个文件 :first 切换至第一个文件 退出 :qa 全部退出2.分屏显示一个文件
Ctrl+w,松开后按, s:水平拆分窗口 Ctrl+w,松开后按, v:垂直拆分窗口 在窗口间切换光标: Ctrl+w,松开后按,ARROW(上下左右键) :qa 关闭所有窗口3.分窗口编辑多个文件
vim -o :水平分割显示 vim -O :垂直分割显示4.将当前文件中部分内容另存为另外一个文件
末行模式下使用w命令 :w :ADDR1,ADDR2w /path/to/somewhere5.将另外一个文件的内容填充在当前文件中,合并两个文件
:r /path/to/somefile
九、高级设定
1.显示或取消显示行号(仅对当前vim进程有效)
# number=nu :set nu :set nonu2.忽略或区分字符大小写【不常用】
# ignore character =ic :set ic :set noic3.设定自动缩进
# autoindent = ai :set ai :set noai4.查找到的文本高亮显示或取消
:set hlsearch :set nohlsearch5.语法高亮
:syntax on :syntax off6.编辑配置文件
/etc/vimrc:对所有用户都生效 ~/.vimrc:对当前用户生效
想学习VIM的使用?请使用内置的vimtutor!
十、问题
有时用vim编辑没有保存就关上了shell,那么下一次再打开会警告: 让你选择用只读方式打开、强行编辑、删除、退出等 而且每次都会提醒,此时会发现在原始文件file旁,会有一个新的file.tmp文件, 将它删除就不会再提示了
磁盘管理:
学好磁盘管理,会对以后自己处理服务器硬盘问题大有裨益
硬盘:
我们每天打交道最多的可能就是硬盘了,只要你开机,硬盘就开始通电工作,可能那会还没来得及开显示器,硬盘就已经在BIOS自检后启动了操作系统,这一切似乎在很短的时间内就完成了。但是它靠的却是机箱里厚重质感的大块头——硬盘
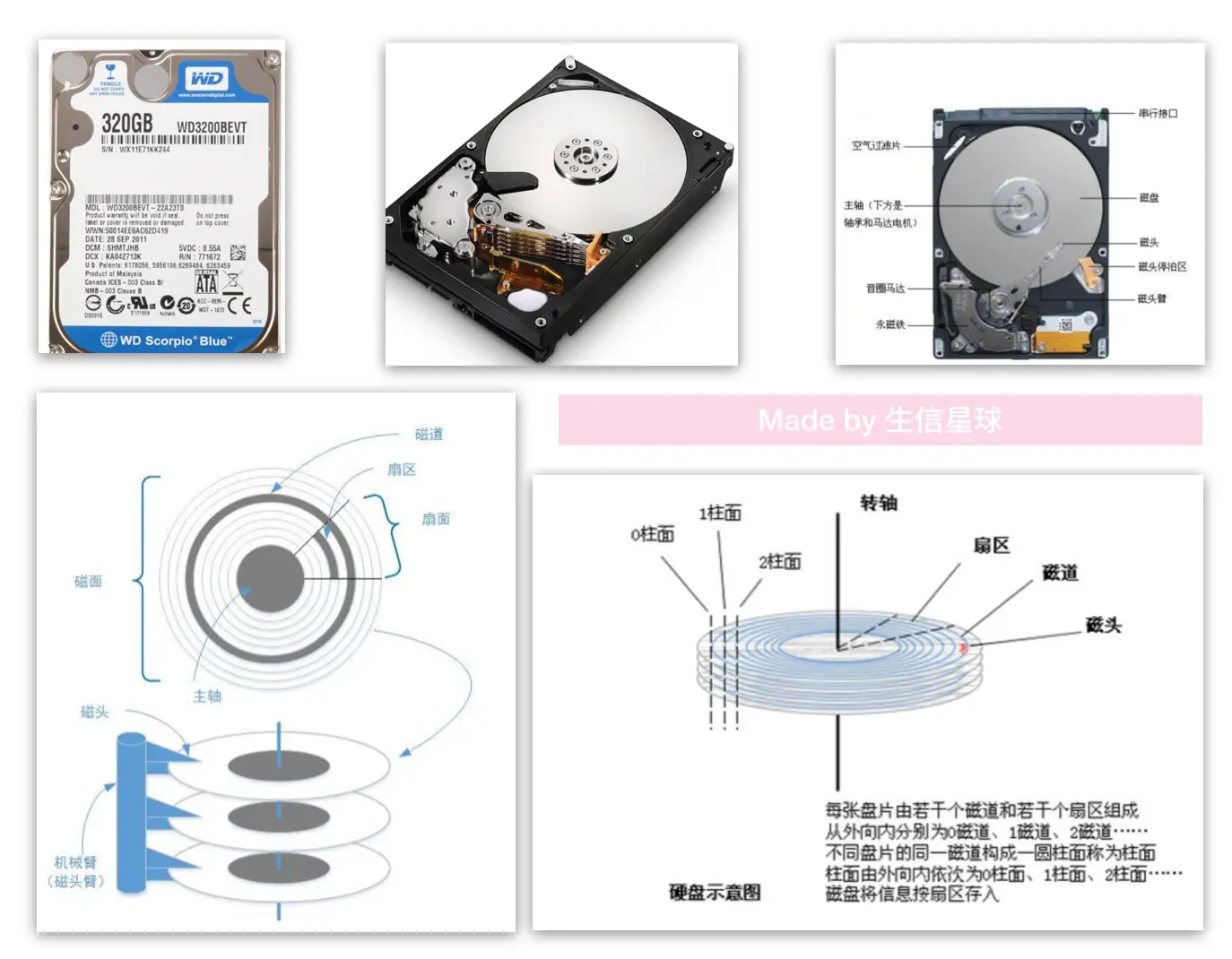
硬盘长什么样? 喜欢DIY的朋友应该都了解过,但是大部分用户应该没有见过机箱内的硬盘,或者不清楚其内部构造 先看几张图养养眼~
硬盘物理结构相关概念:
数据如何存储的: 磁盘天生并不会记录什么照片、文档文字等,它知道的只有0和1,硬盘有很多磁盘叠在一起,但相互之间又有间隔,通过改变磁盘的磁化方向来存数0和1,这样记录数据
磁头(head)数:每个盘片有上下两面,各对应1个磁头,实现数据的存取
磁道(track):当磁盘旋转时,磁头保持在一个位置上,每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道。将最外侧道的编号为0,向内+1 【接下来把磁道想象成跑道,会容易理解的多】
柱面(cylinder):不同盘片的相同编号的磁道构成的圆柱面就被称之为柱面【柱面数=一个盘面的磁道数】 【简单说,磁盘就相当于立体的操场,从上到下有很多0跑道,1跑道等 而柱面就是将各个层的同一编号跑道们汇集在一起的称呼】
扇区(sector):每个磁道都别切分成很多扇形区域,每个磁道的扇区数量相同,每个扇区大小为512字节 【比如:每个跑道有400米,我们从中可以切分成许多的5.12米,这就是扇区】
平均寻道时间:【就是跑完一圈跑道用的时间】 硬盘在接收到系统指令后【起跑口令】,磁头从开始移动到数据所在的磁道所花费时间的平均值。 它在一定程度上体现了硬盘读取数据的能力【相当于运动员的身体素质】,是影响硬盘内部数据传输率的重要参数,单位为毫秒(ms)。 【一般PC为7200RPM; 笔记本5400RPM】 外面柱面速度比内部的快【不难理解:外侧跑道的运动员和内侧跑道的的运动员两个人同时到达终点,当然外侧跑道跑得更快】,所以将一些频繁访问的内容放在靠近外部的柱面,比如C盘。
硬盘容量 我们平时所说的几百G甚至上T的硬盘,是这么计算得来的 硬盘的容量=柱面数×磁头数×扇区数×512(字节数) 1T = 1024G = 1024^2^ M = 1024^3^K = 1024^4^B(字节)
硬盘的内部逻辑结构:
MBR(Main Boot Record)
这是硬盘最核心的代码,没有了它,硬盘中的数据都会丢失
中文名“主引导记录”,它是位于磁盘最前边的一段引导代码,它是生产厂商出厂时对磁初步格式化加入的【Born with loader code】。
职责:负责磁盘操作系统(DOS)对磁盘进行读写时分区合法性的判别、分区引导信息的定位【总指挥的角色】
组成:三个部分组成(共占用512个字节):
446bytes: BootLoader, 引导程序
64bytes: 每16bytes标识一个分区,所以最多只有四个主分区
主分区+扩展分区<=4 扩展分区最多只有一个
选择只有两个:三主一扩展或四个主分区,否则剩余未分区的空间将无法使用
2bytes: 魔数Magic Number,标记MBR是否有效
如何启动的操作系统:【从0到1的过程】
- 开机CPU加载BIOS自检,完成后,根据BIOS中设定的启动次序,依次查找启动设备的MBR,没有MBR就找下一个设备,有MBR但坏了则系统报错,无法启动;
- 先将BootLoader加载到内存中,BIOS退出,BootLoader程序首先读取分区表(就是上面介绍的64bytes的各个分区)根据配置,加载对应分区上操作系统的内核 【没有分区表则无法找到操作系统】;
- BootLoader会将内核读进内存,内存读入并解压缩BootLoader将控制权交给内核,内核开始启动自身,根据文件配置找到文件系统在什么地方,找到所需要运行的程序的位置,最终完成启动操作系统。
如何实现硬盘快速读取?
想象一个浩大的图书馆,你想找一本书,一般有两种方法: 1.从进门开始一本一本找,想象也知道,可以实现但是太耗时 2.使用索引目录,比如我想找的书是L开头的,就去L区
硬盘也是如此,创建完分区后,就是利用文件系统快速搜索文件
文件系统是一个管理软件,它存储在磁盘某个位置上,不在分区上,但它指向的数据在分区上。 它能够把一个分区划分成两片,元数据存储区+数据存储
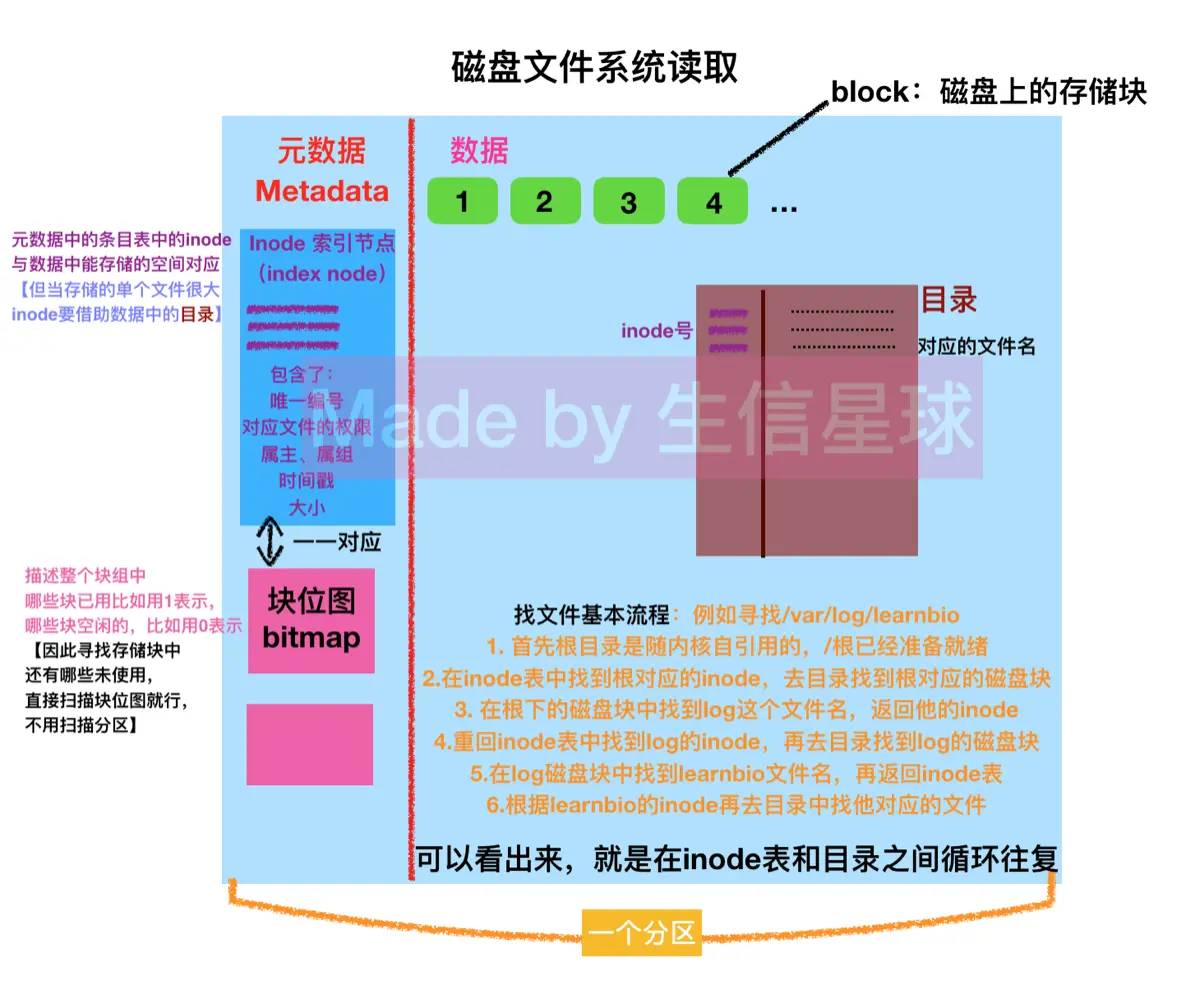
如果要存储文件怎么办? 核心就是找空闲存储块 如何删除文件呢?
删除文件对应的条目
把目录中文件对应的inode在块位图中标记为空 【可以就重新利用这个空块位了,只需要再次覆盖】 【重新建新文件,只是将原来的数据块内容覆盖】
对应的磁盘块虽然标记为空,可以继续使用,但里面的数据没动数据恢复工具就是利用这个原理恢复的
所谓的“文件粉碎机、强力删除”其实就是利用一大堆的随机数据,把磁盘覆盖掉了,比如用一大堆0把原来文件占据的数据块全填满【可不是简单的标记数据块为0哦】
文件复制与剪切:
你是否发现了在一个盘内复制文件比剪切要慢?
原因就是: 复制是在新分区上建立一个新文件,在老分区上把文件复制过去,然后把老分区的删掉: 剪切:就是把文件的目录调整了一下,inode没换,数据没换 【这仅仅对于同一个分区内的文件来讲,换一个分区和复制速度差不多】
硬连接和软链接:
硬链接:
- 直接指向同一个inode的不同路径,彼此之间就叫硬链接
【删除其中一个不影响访问另一个】
- 创建:
ln 原路径SRC 目标路径DEST - 只能对文件创建,不能应用于目录
- 不能跨文件系统
- 创建硬链接会增加文件被链接的次数
软链接:
- 一个路径指向的inode,存储的是另一个路径
- 创建:
ln -s SRC DEST - 如果删除了SRC,链接文件也不能访问
- 可应用于目录,可以跨文件系统
- 不会增加被链接文件的链接次数
- 软链接文件大小为指定的路径所包含的字符个数
文件系统管理:
du:显示一个文件或目录占据系统整体空间大小- -s :(summarize)显示整个目录大小
- -h:human-readable,以K、M、G显示
df:显示磁盘分区上的可使用的磁盘空间- -h:同上
- -P:不换行显示
- -i:显示inode使用情况
设备文件:
- b:按块为单位,随机访问的设备;如:硬盘
- c:按字符为单位,线性设备 如:键盘
- 创建设备文件:
mknod
硬盘设备的设备文件名: IDE、ATA:以hd开头 SATA(Serial ATA):sd开头 SCSI:sd开头 USB:sd开头
同一类型下的不同设备用a,b,c区别 分区:1-4表示主分区,5以后的数字代表逻辑分区
查看当前系统识别了几块硬盘:
fdisk -l后接具体硬盘名,可以查看特定硬盘信息输入fdisk 会出来交互式界面--Ctrl和删除键连用可以删除刚输入的参数 p:显示当前硬件的分区,包括没保存的改动 n:创建新分区 e: 扩展分区(extended) p: 主分区(primary) d:删除一个分区 w:保存退出 q:不保存退出 t:修改分区类型 L: 跟在t后使用,显示所支持的所有类型 # 如改为swap需要,L命令,输入Linux swap / Solaris 的编码(82)用这种方法创建完新分区后,此时内核仍未识别,
cat /proc/partitions查看分区列表, 重读添加新建的分区,用partprobe /dev/sda命令;之后才能进行高级格式化Linux 下的VFS VFS是虚拟文件系统(Virtual Filesystem Switch),也存在内核空间中
虚拟,是因为它所有的数据结构都是在运行以后才建立,并在卸载时删除,而在磁盘上并没有存储这些数据结构 因此,只有与实际的文件系统,如Ext2、Minix、MSDOS、VFAT等相结合,才能开始工作
创建文件系统
mkfs: make file systemcat /proc/filesystems查看当前内核所支持的文件系统类型 例如:ext2、ext3、vfatmkfs -t 文件类型 /dev/新建的分区【⚠️不要对已有数据的分区创建文件系统,因为此操作等于快速格式化】
mke2fs专门挂载EXT系列文件-j:创建ext3类型文件系统; -b BLOCK_SIZE:指定块大小,默认为4096,可用取值为1024、2048或4096; # 经常存储的小文件适合用小的,大文件用大的 -L LABEL:指定分区卷标,有了卷标,下次重新开机多个挂载的硬件设备次序不会乱,且可用卷标来引用该分区; -m <数字>:指定预留给超级用户的预留百分比,默认为5%; -N:指定inode个数;blkid查询设备上所采用文件系统类型、UUID等e2label查看或定义卷标e2label 设备文件 卷标:设定卷标tune2fs无损调整文件系统的相关属性-j:不损害原有数据,将ext2升级为ext3;# 块大小属性不能更改 -L LABEL:设定或修改卷标; -o:设定默认挂载选项;acl -m <数字>:调整预留给超级用户的预留百分比; -C <数字>:每挂载n天后进行自检,0或-1表示关闭此功能。fsck检查并修复LINUX文件系统-t FSTYPE:指定文件系统类型-a 自动修复e2fsck专门检查并修复EXT2、EXT3文件系统-p:自动修复;-f:强制修复
挂载与卸载
挂载:将新的文件系统关联至当前根文件系统 卸载:解除某文件系统与当前根文件系统的关系
格式化硬盘后,使用mount
mount 设备 挂载点
设备:
设备文件:/dev/sda5
卷标:LABEL=""
UUID:UUID=""
挂载点:即目录
要求:
1.此目录没有被其他进程使用;
2.目录事先存在;
3.目录中的原有文件将会暂时隐藏;
# 挂载完成后,要通过挂载点访问对应系统上的文件
mount -a 挂载所有/etc/fstab中的设备
卸载用unmount
umount 设备
umount 挂载点
注意:挂载的设备没有进程使用;
物理内存和交换空间使用情况
swap交换空间: 由于进程某段时间内过多,导致系统的物理内存不够用的时候,如果没有多余进程存放位置,主机有可能会宕机。因此~物理内存会寻找一些很长时间没有什么操作的程序, 将他们的内存使用空间移动到硬盘中的一块位置上。这块为了内存应急的空间就是swap。 【当那些被释放的出来的程序要运行时,再从硬盘Swap分区中恢复保存的数据到内存中】
free来查看-h:human-readable
- 创建swap
fdisk /dev/sda创建新分区,格式化的时候调整分区类型为82(Linux swap)【不调整,默认使用83Linux】partprobe /dev/sda重读分区mkswap /dev/sda8 -L LABEL进行格式化,指定卷标LABELswapon /dev/sda8启动交换分区 【关闭用swapoff】
- 创建swap
dd 比cp更强大的复制命令
# cp是以文件为单位进行复制的;
# dd直接复制的文件代码,因此可以复制文件的一部分
if=数据来源 【input file】
of=数据存储目标 【output file】
bs=1 一次复制多少字节 【指定单位:bs=1M】
count=2 一共复制几次
dd复制备份MBR:
# 复制硬盘最开始的512的字节,那也就是核心程序MBR
dd if=/dev/sda of=/mnt/usb/mbr.backup bs=512 count=1
# 恢复
dd if=/mnt/usb/mbr.backup of=/dev/sda bs=512 count=1
文件系统配置文件
文件系统的配置文件
/etc/fstab:系统在初始时,会自动挂载此文件中定义的每个文件系统,文件内容从左到右为:要挂载的设备 挂载点 文件系统类型 挂载选项 转储频率 文件系统检测次序 /dev/sda5 /mnt/test ext3 defaults 0 0 #转储频率<数字>(每多少天做一次完全备份,0表示不备份) #文件系统检测次序(只有根可以为1,0表示不检查)
fuser验证进程正在使用的文件-v:查看某文件上正在运行的进程 fuser -km MOUNT_POINT:终止正在访问此挂载点的所有进程