009-R与进化树
刘小泽写于18.7.10 今晚听了Y叔之前的学术分享视频R与ggtree,想和你分享
1. problems and issues
进化领域中树这个文件结构是比较复杂的,构建树的过程就是把数据关联到文件格式中便于可视化的过程,这种关联格式主要有:
标准格式之一 newick
标准格式之二 nexus:软件间兼容性不好
其他一些不兼容格式
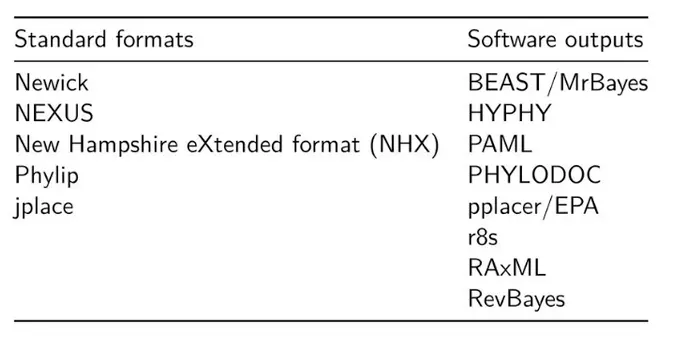
如果只是想推断一棵树,大多数只用mega。但是现在的研究会获得大量的数据(phenotypic data/ experimental data/ clinical data/ analysis data),而且是异质性的,比如采样时间、地点,表型的观察值,实验测量数据等都是可以拿来分析有没有进化上的一些关系,mega远远不够用!但是上面的数据关联格式又不友好~
树的注释:
Figtree,TreeDyn, iTOL etc 这些软件之间也是需要互相写脚本转换格式
- restricted to pre-defined annotating utilities
- focus on specific analyses and data types
- non-overlapping features and hard to customise
2. R与ggtree
ggtree优势:
- 他的设计就是针对不同来源的数据,拿来可以直接注释
- 支持高水平图形语法进行树的注释:比如有一个分类数据,要根据这个对进化树上色,并且不同节点以不同形状变现出来。指定一个变量,ggtree就会做完所有的事情
- 支持多个图层组合,可以画出很复杂的图
- 可以提供用户的私人订制
- 作为R包,能够保证可重复性,自动化,利于同行的交流
为什么要写代码作图,而不是简单的点点鼠标?
同样的数据,代码会赋予它更深的内涵
鼠标操作的都是套路化的东西,你会别人也会,就像公司做的图都很sexy,但是他们并不关系你的数据体现了什么价值。只有在自己通过不断完善代码的过程中,才会对自己的数据有更深的理解,才有可能挖掘更多的信息。 现在有许多一步出图,网站工具出图,很低的学习成本,做的图数量可能也不少,但是很多时候,自己都不知道这些图是怎么出来的,另外低学习成本的工具是不提供太多的拓展空间的。不知道你有没有这样的体会,在网站上做了一个图,很好看,基本符合预期,但是有一些线条形状/颜色或者图例位置需要改动,而网站上也没有这种设置,那么只好自己吭哧吭哧用PS、AI去编辑。心想:头脑中的图片很清楚,但为什么没有工具能帮我实现他的样子呢?于是,代码的价值就在这里
代码会带给自己一种能力,去探索自己的数据,就像在玩魔方,不同角度的观察就有不同的解答
可视化对于我们的作用:
- 有了结果,需要展示给其他人
- 还没有结果,甚至不知道从何下手,他可以帮你找到一些潜在的研究方向
为什么做生信分析必备R?
- 开源免费
- 很庞大的社区 【Bionconductor 基本你能想到的组学上的东西,别人都能提供帮助】
- 强大可视化功能
R的图形语法目前有两大类:
base:就像纸笔模型【不带橡皮擦】,直接出图做了不能撤销 【打开R就加载】
grid 【包括 lattice + ggplot2】 降低入门门槛; 不直接出图,导出的是一个图形对象,可以继续编辑**【相当于带了橡皮擦】** 画图是画在当前活动窗口
lattice:【安装R时装好,但需要自己加载】 处理多维数据; 使用grid修改细节,比ggplot2简单
ggplot2: 【需要自己安装并加载】 使用图形语法,不用纠结太细枝末节的东西(比如那条线用什么颜色,它会帮你上色); 作图更美观
【图形都是点–线–面组合起来的】 ggplot2最基本的元素:
数据data + 几何对象geom(用于映射数据)+ 坐标(一般都是笛卡尔) geom又包括了: 美学aesthetics:描述了可视化的特征(比如数据中对应点的位置、大小、颜色、形状) 标尺scales:可视化的东西如何转为可以显示的值(比如取色范围、点映射范围),比如画气泡图就是把点的映射范围放大
ggplot2作图模版:
ggplot()+ geom_... ([data=data frame] [aes(variable mappings)--关于映射设定] [non-variable adjustments]--全局设定) 下面就是数据和图片的对应关系: 散点图关于Length和Width的,根据Species上色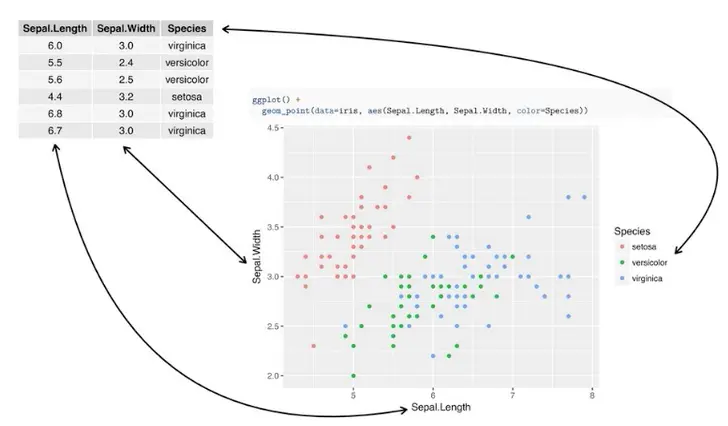
复杂的图片就对应许多的图层layer,就像PS一样: 【这张图看明白,就掌握了ggplot2的精髓,同时对以后使用ggtree也大有帮助】
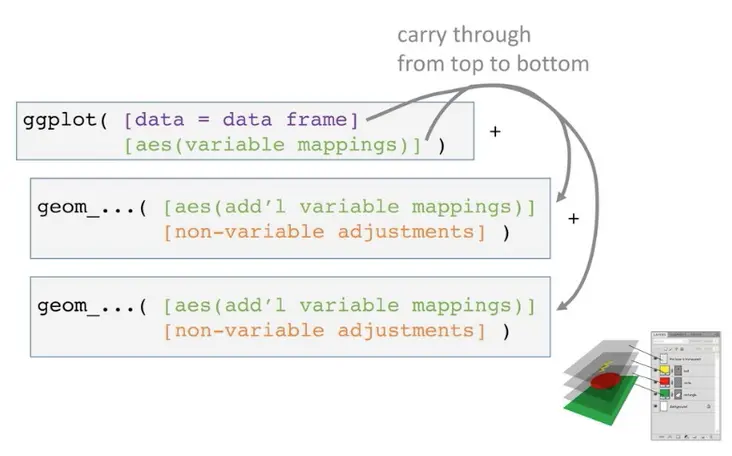
归根结底:时刻记着做图的目的,是要呈现数据,而不是把图搞得多么漂亮。数据可视化的精髓在于探索数据~推荐学习ggplot2和grid
3. ggtree的用法
能不能把自己的数据呈现出来对于初学者是非常重要的! 一开始不要纠结于图片的美观,那些东西都可以交给美工处理, 也不要妄想用代码修改图片,因为那会比较复杂,耗时太久导致拖延 大家的脑容量都是有限的,记不住太多的细节,把细节放在外脑就好
树的操作:
viewClade: 对进化分枝操作【画出一个分枝,然后旁边辅之一整棵树作为参考】
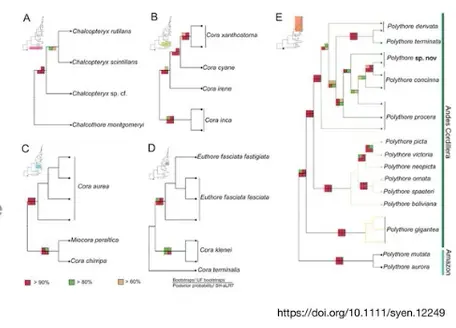
groupOTU & groupClade: 把不同的分枝放在一起,赋予不同的颜色、线条
scaleClade: 把分枝变大或变小
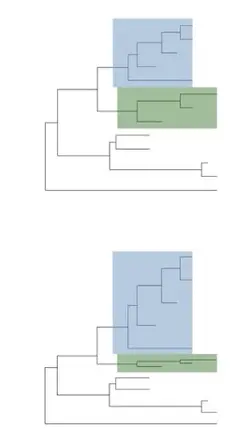
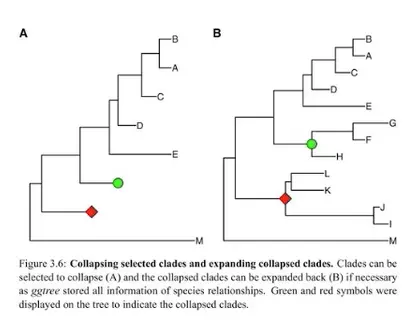
collapse & expand: 不展示某些不需要的节点具体分枝【可以逆向操作】
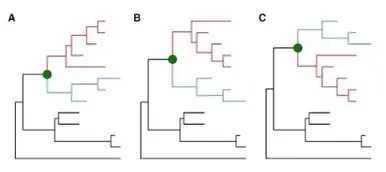
rotate & flip: 可以把一个分枝旋转180度
open_tree & rotate_tree: 把圆圈的树弄一个开口,然后还能旋转,弄成一个扇形
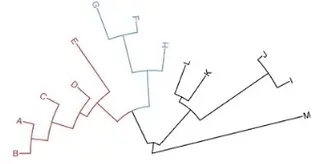
rescale_tree: 更改树的范围区间,可以放大可以缩小,并且可以用不同颜色表示不同范围区间的树
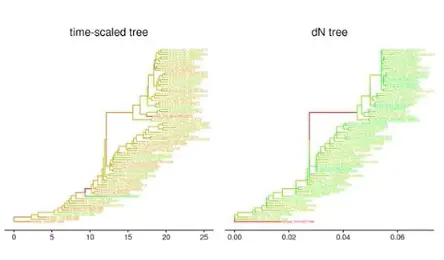
树和数据怎么结合?
两种需求:
- 把数据比对到树上,在树上展示数据 Mapping data to the tree structure; 【图中的各个颜色的点就是比对到树上的数据,几组数据就用几个图层】
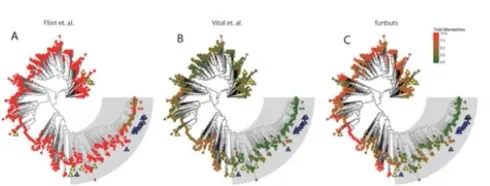
- 自己有数据并把他们做了可视化,但是想把数据的图和进化树对应拼接在一起【并非简单拼接两张图!要是要画出点图/箱线图/小提琴图等等来匹配树,或者根据树的结构重构数据的图】 Aligning graph to the tree based on tree structure
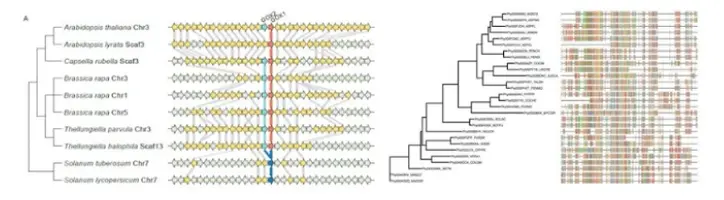
两种方法:
- 对于第一种需求:使用
%<+%插入一个数据到树的图层中去 - 对于第二种需求,使用
facet_plot分面画图,会把数据放到树中自动调整
- 对于第一种需求:使用
ggtree的拓展
emojifont包、seqcombo
编程的语言学习
就想学习日常语言一样,我们除了母语还会学其他的语言,但是遇到什么问题第一时间反应就是说母语。编程语言也是如此,找一个自己领域社区最常使用的python/perl/R等,再深入学习,保证他能成为你的母语,让你有什么问题第一时间就想用它解决,这样就算学好了编程语言