scRNA-单细胞转录组学习笔记-10-乳腺癌领域之PAM50分类
刘小泽写于19.7.8-第二单元第八讲:乳腺癌领域之PAM50分类 笔记目的:根据生信技能树的单细胞转录组课程探索smart-seq2技术相关的分析技术 课程链接在:http://jm.grazy.cn/index/mulitcourse/detail.html?cid=53
什么是PAM50
首次接触这个名词肯定很蒙,因为它是乳腺癌领域的分类名词,需要看许多资料才能了解,我也一样,看了一些推文、英文资料、文章,才做了一些总结
PAM50的意思是Prediction Analysis of Microarray 50 ,可以看到是芯片时代的产物了,它是2009年由Parker提出的,原文在:https://ascopubs.org/doi/full/10.1200/JCO.2008.18.1370,目前接近3000引用量。
使用的芯片是Agilent human 1Av2 microarrays or custom-designed Agilent human 22k arrays,数据在GSE10886,它研究了189个prototype samples,得到了一个50个分类基因与5个对照基因的RT-qPCR定量结果,得到4个gene expression–based “intrinsic” subtypes:Luminal A, Luminal B, HER2-enriched and Basal-like(详见:https://genome.unc.edu/pubsup/breastGEO/pam50_centroids.txt)。

关于这几种分子亚型的介绍:https://www.breastcancer.org/symptoms/types/molecular-subtypes
Luminal A:hormone-receptor positive (estrogen-receptor and/or progesterone-receptor positive), HER2 negative, low levels of the protein Ki-67 => grow slowly and have the best prognosis.
Luminal B:hormone-receptor positive (estrogen-receptor and/or progesterone-receptor positive), either HER2 positive or HER2 negative,high levels of Ki-67 => grow slightly faster than luminal A & prognosis is slightly worse
Triple-negative/basal-like: hormone-receptor negative (estrogen-receptor and progesterone-receptor negative) , HER2 negative
More common with BRCA1 gene mutations among younger and African-American women..
HER2-enriched: hormone-receptor negative (estrogen-receptor and progesterone-receptor negative), HER2 positive => grow faster than luminal cancers & worse prognosis
BUT often successfully treated with targeted therapies aimed at the HER2 protein (e.g. Herceptin, Perjeta, Tykerb, Nerlynx, Kadcyla)
Normal-like: similar to luminal A => prognosis is slightly worse than luminal A but also good
乳腺癌发育来自两种不同的细胞:基体细胞和管腔细胞,还有不同的激素类型(ER/PR、HER2受体),之前在临床上都是根据一些IHC marker来进行分类
The most common immunohistochemical breast cancerprognostic and therapeutic markers used include: estrogen receptor, human epidermal growth factor receptor-2, Ki-67, progesterone receptor, and p53. (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4127609/)
乳腺癌是一个高度异质性的疾病,即使临床分期和病理分级相同,患者对治疗的反应和预后也是不同的。目前仍然是根据临床病理特点如HER2表达、雌激素受体状态、肿瘤大小、分级和淋巴结转移等选择辅助治疗,包括化疗,内分泌治疗,抗HER2治疗等。为了指导预后,常常采用 TNM分期、临床病理指标,后来由于高通量数据的产生,多基因预测成为了一个新途径。
举个例子:可以看表达量,比如有50个基因,有10个特定基因高它们就表示Luminal A,有其他10个基因高就是Luminal B,这就是一个模式;我们只需要比较我们的表达矩阵和这个模式进行对应
多基因检测有两项已经通过了FDA的批准:
- 21-gene OncotypeDx assay (Genome Health Inc, Redwood City, CA):risk stratify early-stage estrogen receptor (ER) –positive breast cancer
- 70-gene MammaPrint (Agendia, Huntington Beach, CA):ER-positive and ER-negative early-stage node-negative breast cancer.
另外前人的研究还有:
- Single Sample Predictor (SSP) :SSP2003 、SSP2006、PAM50
- Subtype Classification Model (SCM):SCMOD1、SCMOD2 、simple three-gene model (SCMGENE)
利用genefu包来熟悉PAM50分类器
这个是Bioconductor的包,使用正确的方式安装好 官方教程在:https://rdrr.io/bioc/genefu/f/inst/doc/genefu.pdf
用包需知 1
自带了5个乳腺癌芯片数据集(breastCancerMAINZ=》 GSE11121、breastCancerTRANSBIG=》 GSE7390、breastCancerUPP=》 GSE3494、breastCancerUNT=》 GSE2990、breastCancerNKI=》数据集没有上传到GEO):https://vip.biotrainee.com/d/689-5
breastCancerMAINZ=》GSE11121
文章:The humoral immune system has a key prognostic impact in node-negative breast cancer. Cancer Res 2008 Jul 1;68(13):5405-13. Sci-hub: https://sci-hub.tw/10.1158/0008-5472.can-07-5206
方法:GPL96(HG-U133A) Affymetrix Human Genome U133A Array芯片,其中包含了200 tumors of patients who were not treated by systemic therapy after surgery using a discovery approach.
临床信息:biological process of proliferation、steroid hormone receptor expression、B cell and T cell infiltration
breastCancerTRANSBIG=》GSE7390
文章:Strong time dependence of the 76-gene prognostic signature for node-negative breast cancer patients in the TRANSBIG multicenter independent validation series. Clin Cancer Res 2007 Jun 1;13(11):3207-14. Sci-hub: https://sci-hub.tw/10.1158/1078-0432.ccr-06-2765
方法: GPL96 (HG-U133A) Affymetrix Human Genome U133A Array 芯片,frozen samples from 198 N- systemically untreated patients
breastCancerUPP=》GSE3494
文章:An expression signature for p53 status in human breast cancer predicts mutation status, transcriptional effects, and patient survival. Proc Natl Acad Sci U S A 2005 Sep 20;102(38):13550-5. Sci-hub:https://sci-hub.tw/10.2307/3376671
方法: GPL96 (HG-U133A) Affymetrix Human Genome U133A Array 芯片,freshly frozen breast tumors from a population-based cohort of 315 women representing 65% of all breast cancers resected in Uppsala County, Sweden, from January 1, 1987 to December 31, 1989.
breastCancerUNT =》GSE2990
文章:Gene expression profiling in breast cancer: understanding the molecular basis of histologic grade to improve prognosis. J Natl Cancer Inst 2006 Feb 15;98(4):262-72 Sci-hub:https://sci-hub.tw/10.1093/jnci/djj052
方法: GPL96 (HG-U133A) Affymetrix Human Genome U133A Array 芯片, 189 invasive breast carcinomas and from three published gene expression datasets from breast carcinomas.
最后一个breastCancerNKI使用的是Agilent公司芯片
用包需知 2
这个R包除了包装了PAM50分类,还加入了其他许多分类标准,详见https://rdrr.io/bioc/genefu/man/,使用PAM50是因为它的引用量很高,认可度较高
开始用包
# 加载数据
rm(list = ls())
options(stringsAsFactors = F)
load(file = '../input.Rdata')
a[1:4,1:4]
head(df)
# 检查行名(基因名)
> head(rownames(dat))
[1] "0610007P14Rik" "0610009B22Rik" "0610009L18Rik" "0610009O20Rik"
[5] "0610010F05Rik" "0610010K14Rik"
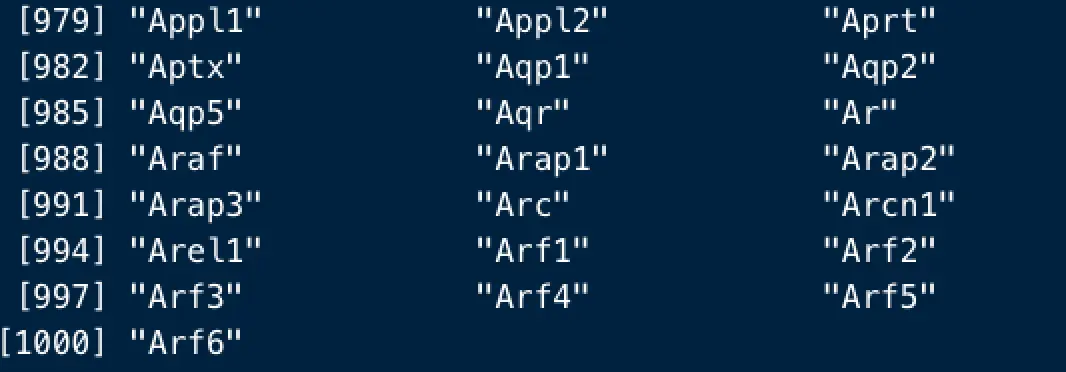
除了很多不像常规基因名的基因以外,还有很多基因大小写不一致,这是因为这个数据是小鼠的,而小鼠的基因名与人类的不同在于:首字母大写,其余小写
首先就是将这里的dat基因名全变为大写
rownames(dat)=toupper(rownames(dat))
当然,最好直接使用小鼠的分类器,但是目前没有,因此只能使用人类的,不是很准确,但是这个分类是可以借鉴的
# 加载genefu
library(genefu)
# 可以看到会加载很多依赖包,包含机器学习、并行、分类法
Loading required package: limma
Loading required package: biomaRt
Loading required package: iC10
Loading required package: pamr
Loading required package: cluster
Loading required package: impute
Loading required package: iC10TrainingData
Loading required package: AIMS
Loading required package: e1071
Loading required package: Biobase
Loading required package: BiocGenerics
Loading required package: parallel
这个包也需要转置后的表达矩阵(基因为列)
> ddata=t(dat)
> ddata[1:4,1:4]
0610007P14Rik 0610009B22Rik 0610009L18Rik 0610009O20Rik
SS2_15_0048_A3 0.000000 0 0 0.000000
SS2_15_0048_A6 0.000000 0 0 0.000000
SS2_15_0048_A5 6.459884 0 0 2.544699
SS2_15_0048_A4 6.313884 0 0 3.025273
> dim(ddata)
[1] 768 12198
> s=colnames(ddata);head(s);tail(s) ##获得基因名
[1] "0610007P14Rik" "0610009B22Rik" "0610009L18Rik" "0610009O20Rik"
[5] "0610010F05Rik" "0610010K14Rik"
[1] "ERCC-00160" "ERCC-00162" "ERCC-00163" "ERCC-00165" "ERCC-00170"
[6] "ERCC-00171"
## 发现有的基因名是不符合常规认知的,因此需要进行基因名转换
# 看下人类这个基因注释包中都包含哪些,发现有org.Hs.egSYMBOL,应该就是需要的
ls("package:org.Hs.eg.db")
# 这个注释信息是Bimap格式的,需要先转换成数据框,利用toTable函数
> class(org.Hs.egSYMBOL)
[1] "AnnDbBimap"
> s2g=toTable(org.Hs.egSYMBOL)
# 求小鼠的基因与人类的基因的交集,利用match函数,返回位置信息(如果没有对应,就返回NA)。存在NA的原因就是:小鼠有的对应不上人类基因名,并且人类的基因也有未知的
> g=s2g[match(s,s2g$symbol),1]
# 然后做成一个数据框
> dannot=data.frame(probe=s,
"Gene.Symbol" =s,
"EntrezGene.ID"=g)
# 下面去掉ddata和dannot中NA的行
> ddata=ddata[,!is.na(dannot$EntrezGene.ID)] #ID转换
> dim(ddata)
[1] 768 10487 # 相比之前大约去掉2000个基因
> dannot=dannot[!is.na(dannot$EntrezGene.ID),]
# 看下去除NA后的基因注释和表达矩阵,必须保证注释的基因ID和表达矩阵的基因ID一一对应
> head(dannot)
probe Gene.Symbol EntrezGene.ID
372 A4GALT A4GALT 53947
393 AAAS AAAS 8086
394 AACS AACS 65985
396 AAGAB AAGAB 79719
397 AAK1 AAK1 22848
398 AAMDC AAMDC 28971
> ddata[1:4,1:4]
A4GALT AAAS AACS AAGAB
SS2_15_0048_A3 8.516383 0 0.000000 0
SS2_15_0048_A6 7.111928 0 0.000000 0
SS2_15_0048_A5 3.415452 0 0.000000 0
SS2_15_0048_A4 6.848774 0 7.168196 0
可以进行genefu分析了,分型就是使用molecular.subtyping函数
s<-molecular.subtyping(sbt.model = "pam50",data=ddata,
annot=dannot,do.mapping=TRUE)
# 结果就是将768个细胞
> table(s$subtype)
Basal Her2 LumB LumA Normal
42 58 46 543 79
# 可以利用原始的样本信息数据框df进行clust分组与分子分型之间关系的探索
> df$subtypes=subtypes
> table(df[,c(1,5)])
subtypes
g Basal Her2 LumA LumB Normal
1 36 30 205 13 28
2 3 25 217 31 24
3 1 2 102 1 15
4 2 1 19 1 12
注意:虽然这里可以实现分类,但是PAM50是针对乳腺癌患者进行分类的,而我们这里是针对单细胞;而且细胞也不是癌细胞,是CAFs(cancer associated fiberblast) 不管是什么细胞,最后都能得到一个表达矩阵,算法是不会考虑矩阵来源的,因此即便是正常细胞的矩阵,也可以分类成5种乳腺癌亚型,所以分类的前提还是自己熟悉数据的生物学背景
探索PAM50
看一下pam50,它是一个列表
> str(pam50)
List of 7
$ method.cor : chr "spearman"
$ method.centroids: chr "mean"
$ std : chr "none"
$ rescale.q : num 0.05
$ mins : num 5
$ centroids : num [1:50, 1:5] 0.718 0.537 -0.575 -0.119 0.3 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:50] "ACTR3B" "ANLN" "BAG1" "BCL2" ...
.. ..$ : chr [1:5] "Basal" "Her2" "LumA" "LumB" ...
$ centroids.map :'data.frame': 50 obs. of 3 variables:
..$ probe : chr [1:50] "ACTR3B" "ANLN" "BAG1" "BCL2" ...
..$ probe.centroids: chr [1:50] "ACTR3B" "ANLN" "BAG1" "BCL2" ...
..$ EntrezGene.ID : int [1:50] 57180 54443 573 596 332 644 891 898 991 990 ...
然后取出基因名,存储在centroids中:
pam50genes=pam50$centroids.map[c(1,3)]
# 发现有的基因已经不是标准的symbol了,PAM50是2009年的基因名,因此需要进行修改
pam50genes[pam50genes$probe=='CDCA1',1]='NUF2'
pam50genes[pam50genes$probe=='KNTC2',1]='NDC80'
pam50genes[pam50genes$probe=='ORC6L',1]='ORC6'
以第一个基因为例:https://www.genecards.org/cgi-bin/carddisp.pl?gene=NUF2&keywords=NUF2
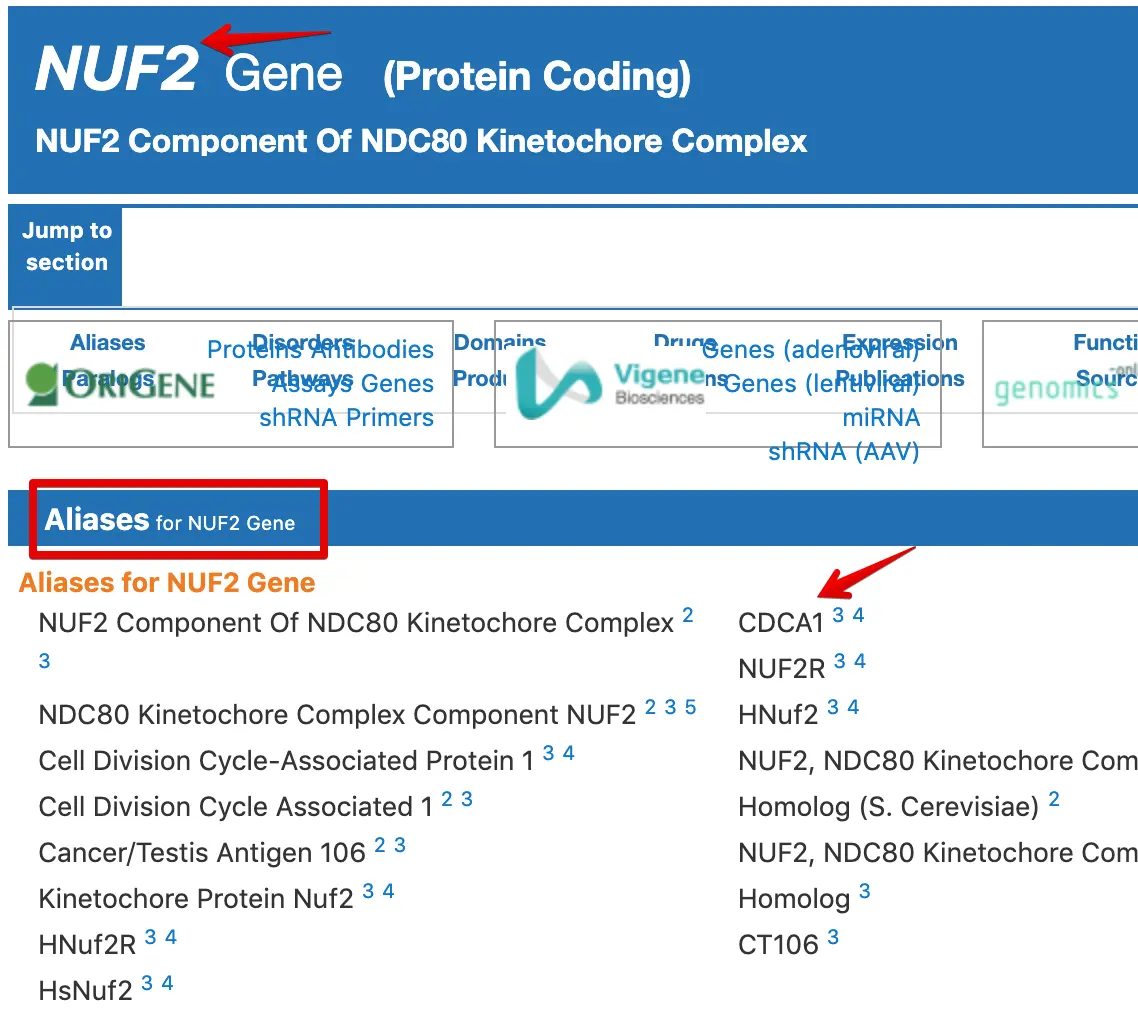
> x=dat
# 找到pam50在原始表达矩阵行名中的基因,发现一共有38个
> pam50genes$probe[pam50genes$probe %in% rownames(x)]
[1] "ANLN" "BAG1" "BCL2" "BIRC5" "BLVRA" "CCNB1"
[7] "CCNE1" "CDC20" "CDC6" "NUF2" "CDH3" "CENPF"
[13] "CEP55" "CXXC5" "EGFR" "ERBB2" "ESR1" "FOXC1"
[19] "KIF2C" "NDC80" "MAPT" "MDM2" "MELK" "MIA"
[25] "MKI67" "MLPH" "MMP11" "MYBL2" "MYC" "ORC6"
[31] "PHGDH" "PTTG1" "RRM2" "SFRP1" "SLC39A6" "TYMS"
[37] "UBE2C" "UBE2T"
> x=x[pam50genes$probe[pam50genes$probe %in% rownames(x)] ,]
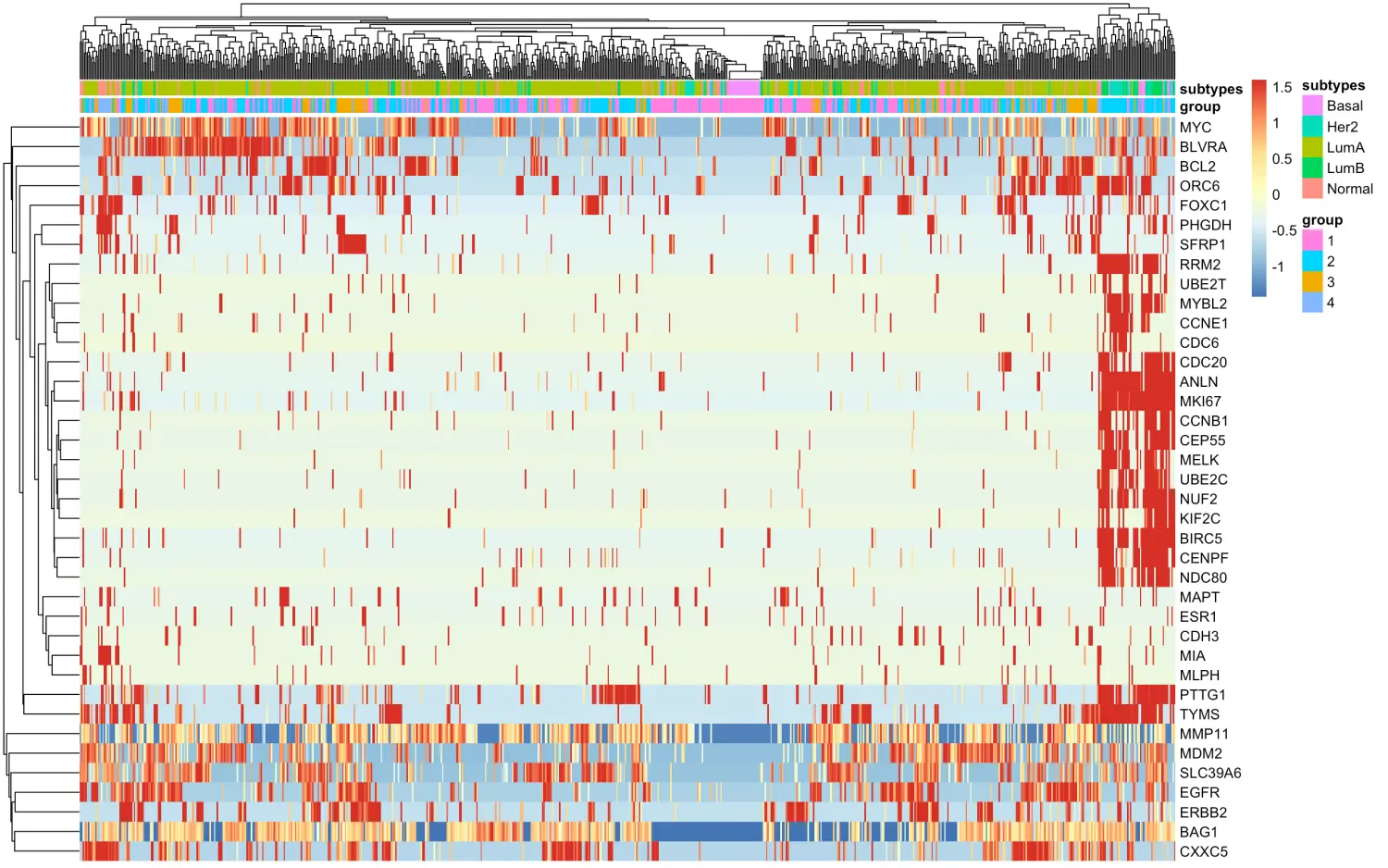
下面进行热图可视化
# 在原来group_list基础上,添加亚型信息,为了下面pheatmap中的anno_col设置
tmp=data.frame(group=group_list,
subtypes=subtypes)
rownames(tmp)=colnames(x)
# 画热图
library(pheatmap)
pheatmap(x,show_rownames = T,show_colnames = F,
annotation_col = tmp)
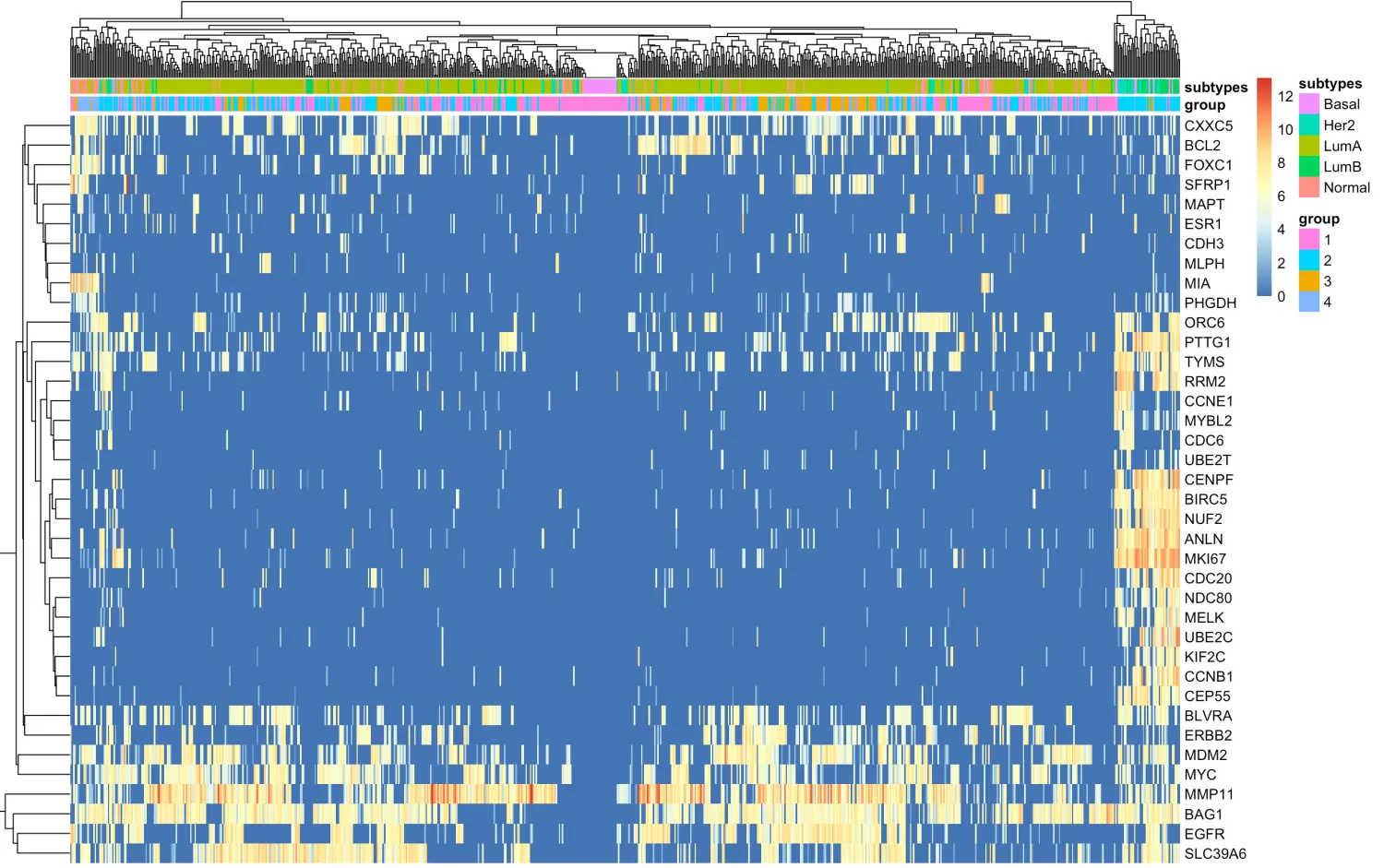
图片本身不重要,因为这里数据的使用是不合适的。可以看到,大部分基因都是luminal A
如果要继续归一化就是:
x=t(scale(t(x)))
x[x>1.6]=1.6
x[x< -1.6]= -1.6
pheatmap(x,show_rownames = T,show_colnames = F,
annotation_col = tmp)