021-作图,你需要ggplot2
刘小泽写于18.8.8
今天遇到一个很简单的需求,但一时间忘了怎么做
前言
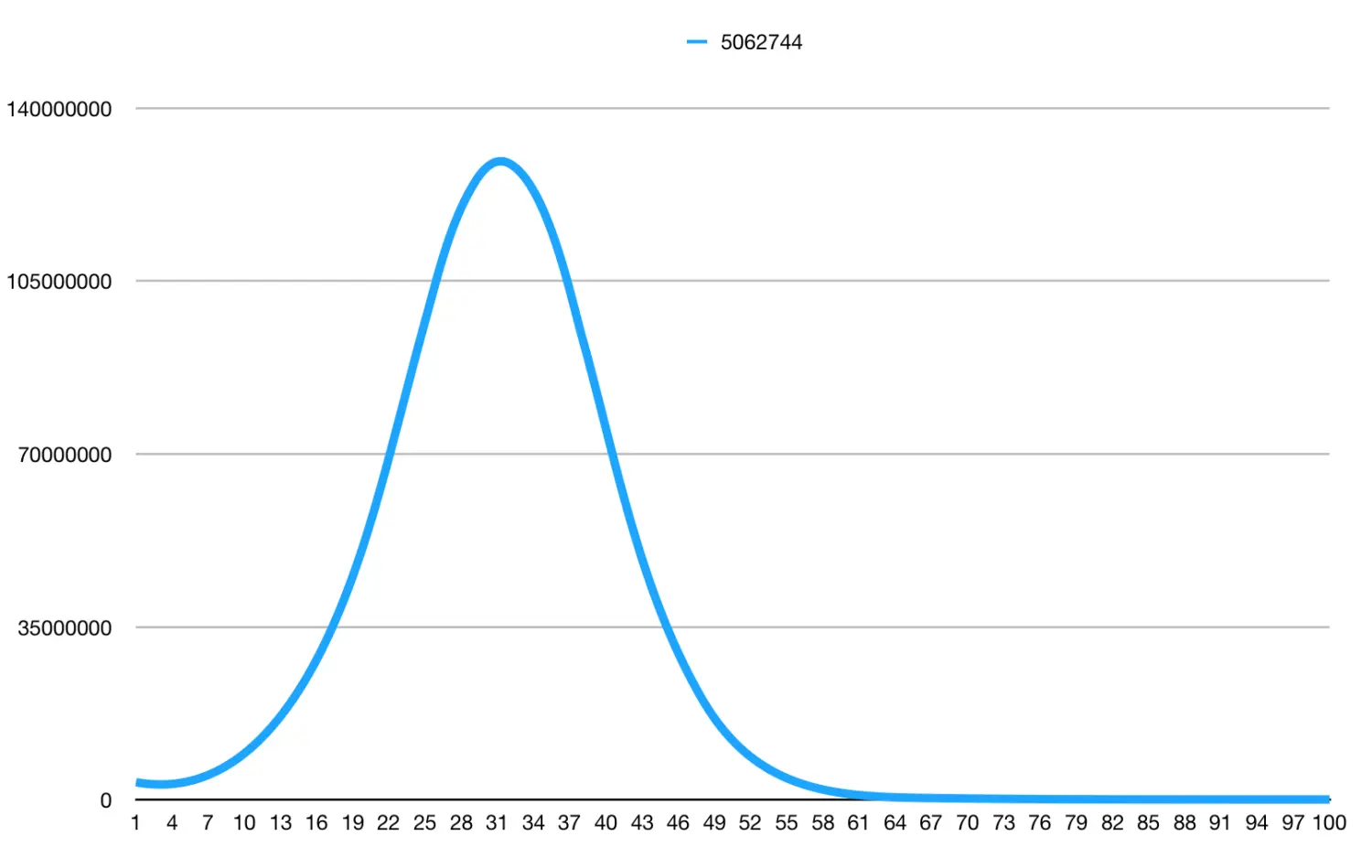
这个表格(只截取了前43)是我最近在学的一个项目中,统计关于一个人类样本中全基因组总体的测序深度信息:左边是测序深度1-100X,超过100的统统归到100plus中;右侧是各个测序深度上的位点数目,比如统计结果显示:有3581433个位点平均测了1次,有5062744个位点平均被测了100多次。
一般人类的基因组测序深度至少要保证30X才能分析SNP和InDel等,因此,这个表格可以反映大体上的测序深度以及全基因组区域中碱基覆盖深度不低于多少X的比例

困惑
要想做出来一条曲线图,用Numbers或者Excel也不是难事,但总想着能不能用R语言来做,用ggplot2来完成呢?毕竟这才是可视化驱动力。【放一张用Numbers做的,能看,但不好看】
好了,那么今天任务就有了
开始学ggplot2
选择的课程是DataCamp 课程 Data Visualization with ggplot2
思考一个问题🤔图是怎么产生的?
一般来讲,一张图中要有以下几部分内容:
| 图表元素 | 含义 |
|---|---|
| Data | 要被绘制的数据集 |
| Aesthetics | (翻译是美学)也就是对数据投射到画布上的设置 |
| Geometrics | 点线面~以什么组合形式来可视化数据 |
| Facets | 将一张图横向或纵向分成小部分 |
| Statistics | 将数据统计后的结果添加到原始图中,增进理解 |
| Coordinates | 坐标信息,定义数据被绘制的空间 |
| Themes | 图形主题,一般设置图形样式 |

我们绘图就是从这些元素中挑选进行组合(当然,这列没有列全)
因此,图是由各个大类中的不同小元素组合而成的
ggplot的绘图有两个特点: 第一,有明确的起始(以ggplot函数开始)与终止(一句话一幅图); 第二,图层之间的叠加是靠“+”号实现的,越后面其图层越高
DataCamp练习界面
起步Introduction
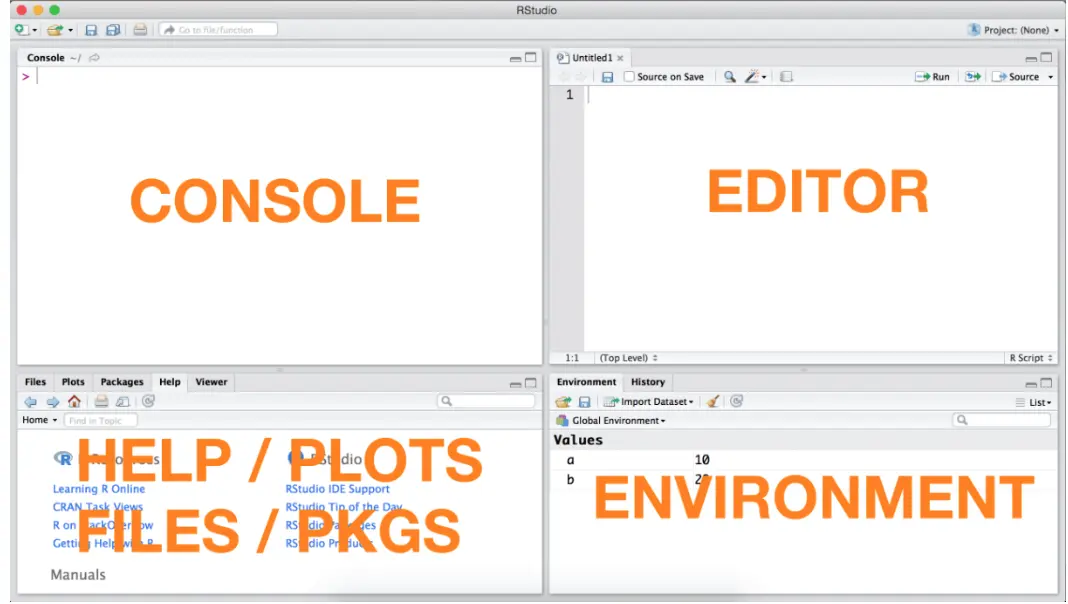
首先要稍微了解R与Rstudio
## 赋值三种方式
a <- 10
a = 10
10 -> a
## 查看数据类型
class(a) #numeric
## 如果想要“10”这个字符而不是数字
a <- as.character(a)
class(a)
## R有哪些类型呢?
## 变量类型
#character - 字符串
#integer - 整数
#numeric - 整数+小数
#factor - 用来分类或者计数
#logical - 逻辑型(Boolean)
#complex - 复数
##数据类型
#vector - 向量(同一种的许多元素集合)
#matrix - 矩阵(多列,但只能是一种变量类型)
#data.frame - 数据集(多列,可以是多种数据类型)
#list - 列表(容纳各种不同的种类和长度的对象objects)
R包,R包,R包以包包
#安装
install.packages("car")
#加载
librara(car)
require(car)#另一种方式
#查看所有R包
library()
#查看帮助信息
library(help=car)
好像越写越不对,看差了教程,整到R快速入门里去了; 没事,先写完再说
工作路径
getwd() #gets the working directory
setwd(dirname) # set the working directory to dir name
导入导出数据
# 导入 "|" 分隔的 .txt file,设置三列的种类class
myData <- read.table("/home/myInputData.txt", header = FALSE, sep="|", colClasses=c("integer","character","numeric")
# 导入一个csv文件(Comma-separated values),然后导出
myData <- read.csv("/home/myInputData.csv", header=FALSE)
write.csv(rDataFrame, "/home/output.csv") # export
查看、删除对象
a = 5
b = 20
ls()#查看所有环境中的对象
rm(a)#删除a
rm(list = ls())#删除全部对象
新建一个环境
rm(list=ls())
env1 <- new.env() # 创建新环境
assign("a", 3, envir = env1) # 在env1中指定a为3
ls() # 查看全局的对象【就像一个大框】
ls(env1) # 查看env1环境中对象【大框中套的小框】
get('a', envir=env1) # 取出env1中a的值
向量
##创建向量用c()
##如果创建的向量中有多种数据格式,最后一定要被统一
##例如创建的混合向量中有数值和字符,那么数值会被转成字符
vec1 <- c(1, 2, 13, 4) # 数值型
vec2 <- c("a", "b", "c", NA) # 字符型
vec3 <- c(TRUE, FALSE, TRUE, TRUE) # 逻辑型
引用向量
length(vec1) # 4
print(vec1[1]) # 1
print(vec1[1:3]) # 1, 2, 13
对向量操作
取子集
logic1 <- vec1 < 15 #创建逻辑变量,设置vec1中元素值小于15为真
vec1[logic1] # 提取vec1中满足logic1的子集
vec1[1:2] # 返回前两个
vec1[c(1,3)] # 返回第一个和第三个
vec1[-1] # 返回除了第一个的剩余各个值
排序(两种方式)
sort(vec1)#升序
sort(vec1, decreasing = TRUE) # 降序
vec1[order(vec1)] # 升序
vec1[rev(order(vec1))] # 降序
构建向量序列和重复
seq(1, 8, by = 2) # 每隔两个取一个
seq(1, 10, length=25) # 1-10之间按一定间隔产生25个数
rep(1, 5) # 1重复5次
rep(1:3, 5) # 从1到3重复5次:1 2 3,1 2 3,1 2 3...
rep(1:3, each=5) # 1到3每个重复5次11111,22222,33333
移除缺失值NA
vec2 <- c("a", "b", "c", NA) # 字符型
is.na(vec2) # 有缺失值返回 TRUE
!is.na(vec2) # 有缺失值返回 FALSE
vec2[!is.na(vec2)] # 返回vec2的非缺失值
设置抽样
set.seed(100) # 输入一个任意数,另一方也输入这个数字,保证数据可重复
sample(vec1) # 随机在vec1中抽样
sample(vec1, 3) # 不放回地抽取3个元素
sample(vec1, 5, replace=T) # 抽取1个元素,又放回去,再抽下一个,抽5次
数据框
构建数据框
##平常用的read.csv() 就是把文件读取到数据框
myDf1 <- data.frame(vec1, vec2) # 两列数据框
myDf2 <- data.frame(vec1, vec3, vec4)
内置数据框
library(datasets) # 初始化
class(airquality) # 查看类型
sapply(airquality, class) # 查看各列的类型
str(airquality) # 查看结构,多少行、多少列
summary(airquality) # 对数据框每一列做了上下四分位、中位数、平均数、最值、NA的统计
head(airquality) # 显示前6行
rownames(airquality) # 显示行名
colnames(airquality) # 列名
nrow(airquality) #行数
ncol(airquality) # 列数
合并数据框
cbind(myDf1, myDf2) # 合并列数相同的数据框
rbind(myDf1, myDf1) # 合并行数相同的数据框
取子集
myDf1$vec1 # 取myDf1数据框中vec1向量
myDf1[, 1] # 格式:数据框[行号,列号]
myDf1[, c(1,2)] # 取出1、2列
myDf1[c(1:5), c(2)] # 取出第二列1-5行
根据条件取子集
# 挑出Day 1, 并且排除掉Temp这一列的数据
subset(airquality, Day == 1, select = -Temp)
# 或者这么写
airquality[which(airquality$Day==1), -c(4)]
抽样
set.seed(50)
trainIndex <- sample(c(1:nrow(airquality)), size=nrow(airquality)*0.7, replace=F) # 产生占一个原始数据70%大小的抽样目录
airquality[trainIndex, ] # 获得training data
airquality[-trainIndex, ] # 去掉training data
融合数据框
merge(myDf1, myDf2, by="vec1") # 按照vec1进行融合
paste函数
paste("a", "b") # "a b"
paste0("a", "b") # 连接a、b且中间没有空格, "ab"
paste("a", "b", sep="") # 同上
paste(c(1:4), c(5:8), sep="") # "15" "26" "37" "48"
paste(c(1:4), c(5:8), sep="", collapse="") # "15263748"
paste0(c("var"), c(1:5)) # "var1" "var2" "var3" "var4" "var5"
paste0(c("var", "pred"), c(1:3)) # "var1" "pred2" "var3"
paste0(c("var", "pred"), rep(1:3, each=2)) # "var1" "pred1" "var2" "pred2" "var3" "pred3
其实这里才开始ggplot2
任务一:熟悉数据集格式
#给定一个数据集mtcars,其中包括了32台汽车的信息(共11项内容,每项内容测了32个数据),用str()查看数据集格式
str(mtcars)
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...
任务二:绘制汽车重量与耗油量的散点图
library(ggplot2)
ggplot(mtcars, aes(x = wt, y = mpg)) + #aes代表Aesthetics
geom_point()
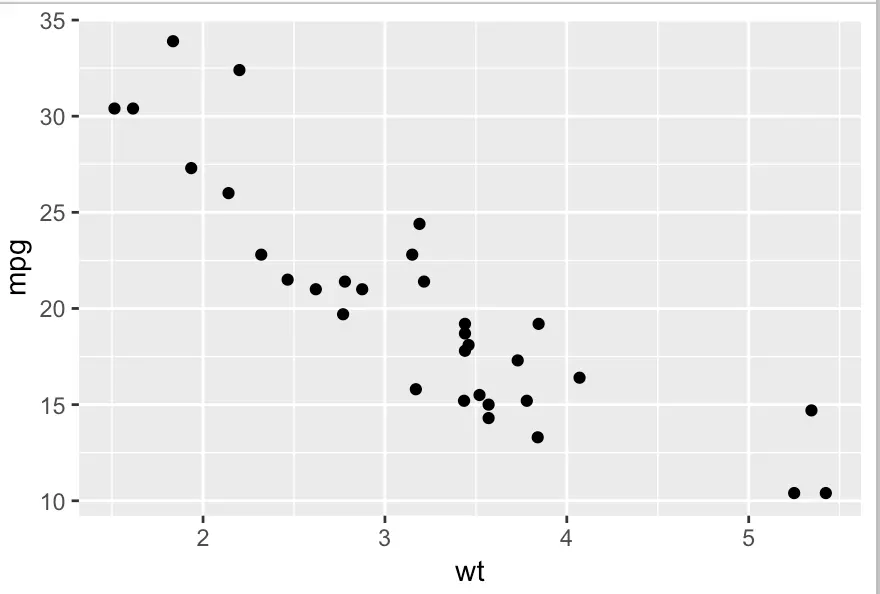
很简单的散点图,但可以再加一组数据disp,让他用颜色表示
ggplot(mtcars, aes(x = wt, y = mpg, color = disp)) +
geom_point()
#或者这里可以用size = disp,按disp表示点的大小
#但是不能用shape = disp,因为disp
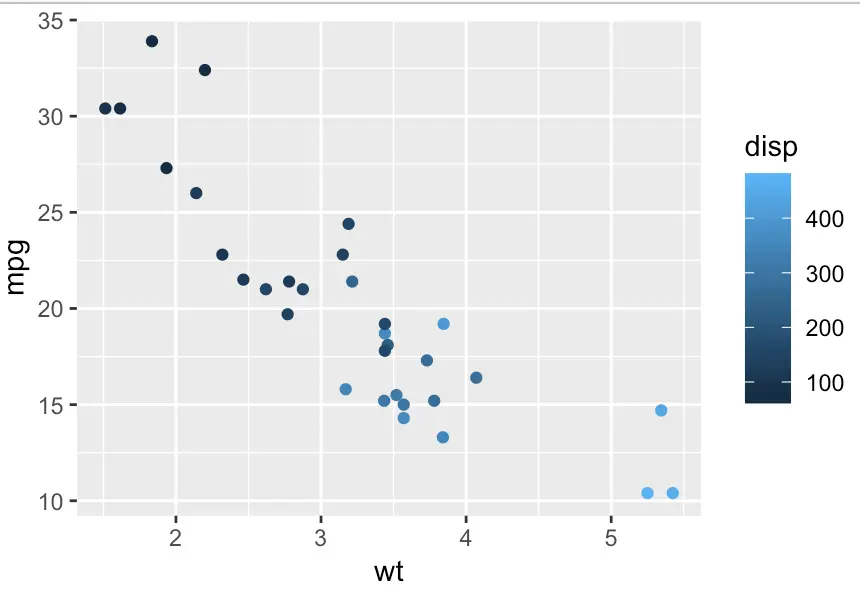
任务三:了解各个层次的关系
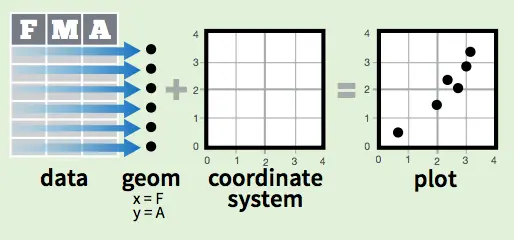
ggplot2基于图形语法,数据集(data)用一系列的图层(geoms)进行标记,再投射到坐标系统上,最简单的无非就是x、y轴图层,geom还能继续拓展
学ggplot2有点入迷了,但今天的任务还是要完成 明天再战!这个图就有一些改观了,主要用代码做的方便重复及批量处理
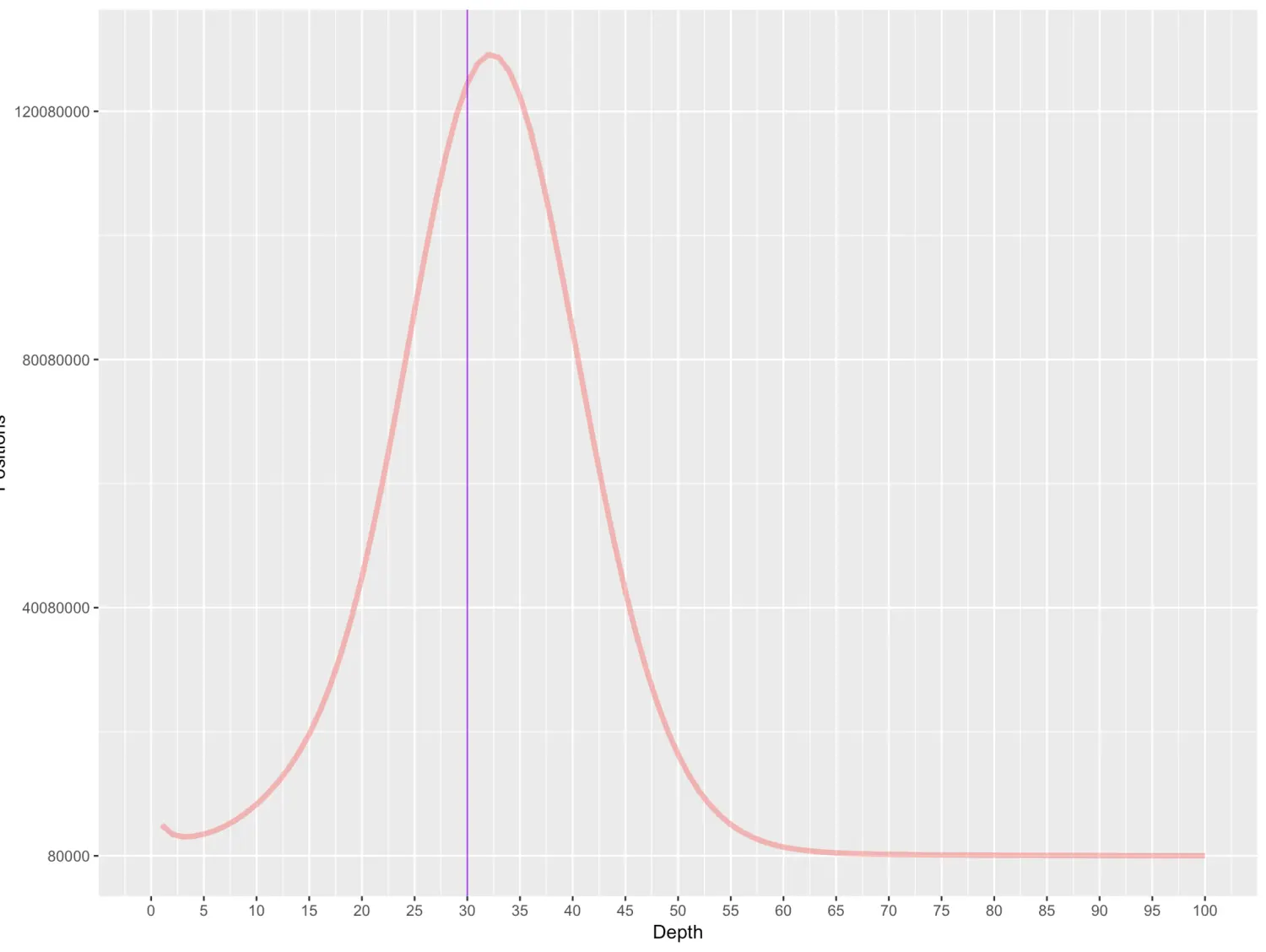
最后放上代码
a=read.table("all_id_depth.txt",stringsAsFactors = T)
ggplot(a, aes(x=1:nrow(a),y=V2,col="orange"))+geom_line(size=1.5,alpha=0.5)+
labs(x="Depth",y="Positions")+geom_vline(xintercept = 30,color="purple",size=0.4)+
scale_x_continuous(limits=c(0,100),breaks=seq(0,100,5))+
scale_y_continuous(limits=c(80000,130000000),breaks=seq(80000,130000000,40000000))