Genekitr
Abstract
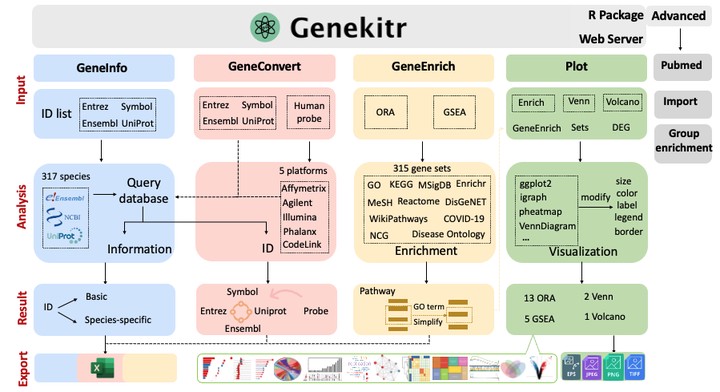
A variety of high-throughput assays including transcriptome, proteome, and metabolism have been developed, producing unprecedented amount of omics data. Regarding studies have contributed to many gene lists, of which the biological significance shall be deeply understood. In spite of this, the manual interpreting of these lists is of large difficulty, especially for non-bioinformatics-savvy scientists. We developed an R package and interactive webserver, Genekitr (https://github.com/GangLiLab/genekitr), to assist biologists in exploring large sets of gene. Genekitr mainly comprises four modules (gene information retrieval, ID conversion, enrichment analysis and publication-ready plotting). At present, the information retrieval module can be capable of retrieving information regarding up to 21 attributes for genes of 317 organisms. The ID conversion module assists in ID mapping of genes, probes, proteins and alias matching. The enrichment analysis module organizes 315 gene sets in different biological contexts by over-representation analysis and gene set enrichment analysis. The plotting module performs customizable and high-quality illustrations that can be used directly in presentations or publications.