186-热图如何去掉聚类树的同时保留聚类的顺序?
刘小泽写于2020.5.15 相信你看到这个问题,可能感觉很简单,不就一个参数的问题吗? 下面来看探索(全程是基于pheatmap来做的)
首先构建一个测试数据
library(pheatmap)
test = matrix(rnorm(200), 20, 10)
test[1:10, seq(1, 10, 2)] = test[1:10, seq(1, 10, 2)] + 3
test[11:20, seq(2, 10, 2)] = test[11:20, seq(2, 10, 2)] + 2
test[15:20, seq(2, 10, 2)] = test[15:20, seq(2, 10, 2)] + 4
colnames(test) = paste("Test", 1:10, sep = "")
rownames(test) = paste("Gene", 1:20, sep = "")
# 20行(基因),10列(样本)的一个表达矩阵
> test[1:4,1:4]
Test1 Test2 Test3 Test4
Gene1 0.6807237 -0.860925078 1.855526 -0.4521751
Gene2 3.9723180 -0.002143337 3.571518 -0.9309492
Gene3 2.8913975 -0.055238202 3.505305 -0.2134826
Gene4 4.6034459 -0.420745550 4.334734 -0.9265620
然后最简单的热图是
p1=pheatmap(test)
p1
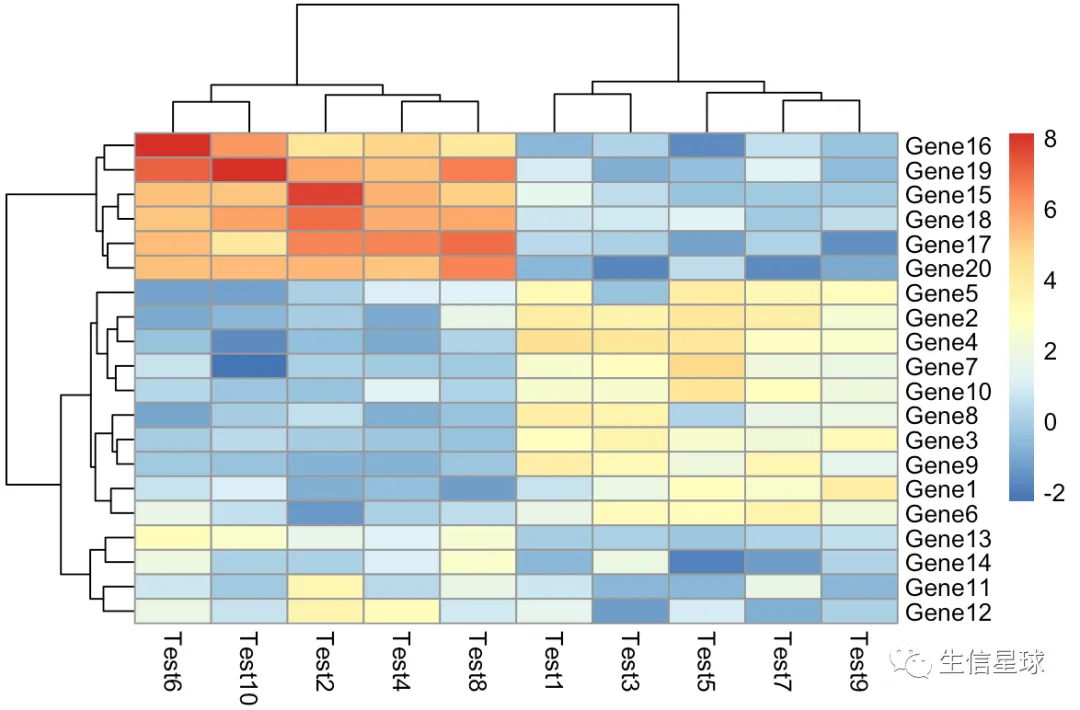
现在看到,这里的样本、基因都进行了聚类,将表达相似的排在了靠近的位置,可以让整个图更美观
但有时候,受限于排版的版面大小以及不关心基因之间的聚类关系,不想要聚类树,但是还是想要上面这种已经排好的位置关系
如果简单调整参数
如果只是简单设置,那么最后的样子也会改变
pheatmap(test,cluster_rows = F,cluster_cols = F)
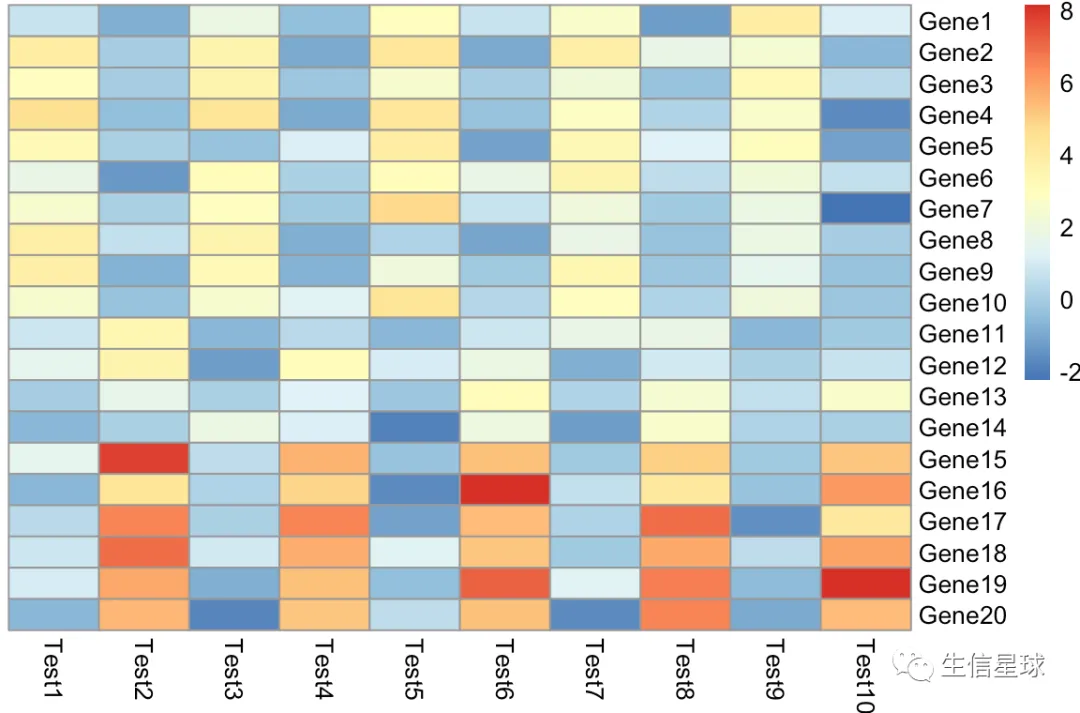
达不到第一张图的效果,基因名和样本名的位置对不起来
情急之下,可能会手动调整基因名和样本名的位置。但毕竟不是有效之举,下次再遇到依旧是个难题…
其实一个小技巧就能拯救
我们为了后面方便保存,经常会把图片保存为一个变量,然后直接运行这个变量就会打印图片;保存这个变量就会另存为不同类型的图片
但是,保存的这个变量不单单是个字母(比如上面的p1),它还暗藏信息
p1默认是对行和列都进行聚类的,因此我们可以从p1中提取到聚类后的行、列结果,而不用手动去挑【重点就是下面两行代码】
gn=rownames(test)[p1$tree_row[["order"]]]
sn=colnames(test)[p1$tree_col[["order"]]]
> gn
[1] "Gene16" "Gene19" "Gene15" "Gene18" "Gene17" "Gene20" "Gene5" "Gene2" "Gene4" "Gene7" "Gene10" "Gene8"
[13] "Gene3" "Gene9" "Gene1" "Gene6" "Gene13" "Gene14" "Gene11" "Gene12"
> sn
[1] "Test6" "Test10" "Test2" "Test4" "Test8" "Test1" "Test3" "Test5" "Test7" "Test9"
稍微看一下,是不是和第一张图的名称是对应的呢
然后如果这时我们再画图呢?
# 按照挑出来的基因和样本号进行重排序
new_test=test[gn,sn]
pheatmap(new_test,cluster_rows = F,cluster_cols = F)
